Metoda componentelor principale sau analiza componentelor(analiza componentelor principale, PCA) este una dintre cele mai importante metode din arsenalul unui zoolog sau ecologist. Din păcate, în cazurile în care este destul de adecvat să se folosească analiza componentelor, este adesea folosită analiza cluster.
O sarcină tipică pentru care analiza componentelor este utilă este aceasta: există un anumit set de obiecte, fiecare dintre acestea fiind caracterizat de un anumit număr (suficient de mare) de caracteristici. Cercetătorul este interesat de tiparele reflectate în diversitatea acestor obiecte. În cazul în care există motive să presupunem că obiectele sunt distribuite între grupuri subordonate ierarhic, poate fi utilizată analiza cluster - metoda clasificări(repartizarea pe grupuri). Dacă nu există niciun motiv să ne așteptăm ca varietatea de obiecte să reflecte un fel de ierarhie, este logic să folosiți hirotonire(aranjament ordonat). Dacă fiecare obiect este caracterizat suficient un numar mare caracteristici (cel puțin atâtea caracteristici care nu pot fi reflectate adecvat într-un singur grafic), este optim să începem studiul datelor cu o analiză a componentelor principale. Cert este că această metodă este în același timp o metodă de reducere a dimensionalității (numărului de dimensiuni) datelor.
Dacă un grup de obiecte luate în considerare este caracterizat de valorile unei caracteristici, o histogramă (pentru caracteristici continue) sau o diagramă cu bare (pentru caracterizarea frecvențelor unei caracteristici discrete) poate fi utilizată pentru a caracteriza diversitatea acestora. Dacă obiectele sunt caracterizate de două caracteristici, se poate folosi un grafic de dispersie bidimensional, iar dacă sunt trei, se poate folosi unul tridimensional. Dacă există multe semne? Puteți încerca să reflectați pe un grafic bidimensional poziția relativă a obiectelor unul față de celălalt în spațiul multidimensional. De obicei, o astfel de reducere a dimensionalității este asociată cu o pierdere de informații. Din diferit moduri posibile Pentru un astfel de afișaj trebuie să îl alegeți pe cel la care pierderea de informații va fi minimă.
Să explicăm ce s-a spus de fapt exemplu simplu: trecerea de la spațiul bidimensional la unul unidimensional. Numărul minim de puncte care definește un spațiu (plan) bidimensional este 3. În Fig. 9.1.1 arată locația a trei puncte pe plan. Coordonatele acestor puncte sunt ușor de citit din desenul în sine. Cum să alegi o linie dreaptă care să transporte maximum de informații despre pozițiile relative ale punctelor?
Orez. 9.1.1. Trei puncte pe un plan definit de două caracteristici. Pe ce linie se va proiecta dispersia maximă a acestor puncte?
Luați în considerare proiecțiile punctelor pe linia A (arată cu albastru). Coordonatele proiecțiilor acestor puncte pe linia A sunt: 2, 8, 10. Valoarea medie este 6 2 / 3. Varianta (2-6 2 / 3)+ (8-6 2 / 3)+ (10-6 2 / 3)=34 2 / 3.
Acum luați în considerare linia B (arată verde). Coordonatele punctului - 2, 3, 7; valoarea medie este 4, varianța este 14. Astfel, o proporție mai mică a varianței este reflectată pe linia B decât pe linia A.
Ce este această cotă? Deoarece liniile A și B sunt ortogonale (perpendiculare), părțile varianței totale proiectate pe A și B nu se intersectează. Aceasta înseamnă că dispersia totală a locației punctelor de interes pentru noi poate fi calculată ca suma acestor doi termeni: 34 2 / 3 +14 = 48 2 / 3. În acest caz, 71,2% din variația totală este proiectată pe linia A și 28,8% pe linia B.
Cum putem determina care linie va avea cota maximă de varianță? Această linie dreaptă va corespunde dreptei de regresie pentru punctele de interes, care este desemnată C (roșu). 77,2% din variația totală se va reflecta pe această linie, iar acesta este maximul sens posibil pentru o anumită locație a punctelor. Se numește o astfel de linie dreaptă pe care este proiectată ponderea maximă a variației totale prima componentă principală.
Și pe ce linie ar trebui să se reflecte restul de 22,8% din variația totală? Pe o dreaptă perpendiculară pe prima componentă principală. Această linie dreaptă va fi și componenta principală, deoarece ponderea maximă posibilă a variației se va reflecta în ea (în mod firesc, fără a se ține cont de ceea ce a fost reflectat în prima componentă principală). Deci asta este - a doua componentă principală.
După ce am calculat aceste componente principale folosind Statistica (vom descrie dialogul puțin mai târziu), obținem imaginea prezentată în Fig. 9.1.2. Coordonatele punctelor de pe componentele principale sunt prezentate în abateri standard.

Orez. 9.1.2. Locația celor trei puncte prezentate în Fig. 9.1.1, pe planul a două componente principale. De ce aceste puncte sunt situate unul față de celălalt diferit decât în Fig. 9.1.1?
În fig. 9.1.2 poziția relativă a punctelor pare a fi schimbată. Pentru a interpreta corect astfel de imagini în viitor, ar trebui să luați în considerare motivele diferențelor de locație a punctelor din Fig. 9.1.1 și 9.1.2 pentru mai multe detalii. Punctul 1 în ambele cazuri este situat la dreapta (are o coordonată mai mare în funcție de primul semn și prima componentă principală) decât punctul 2. Dar, din anumite motive, punctul 3 din locația inițială este mai jos decât celelalte două puncte ( are cea mai mică valoare caracteristica 2) și mai sus decât alte două puncte din planul componentelor principale (are o coordonată mai mare de-a lungul celei de-a doua componente). Acest lucru se datorează faptului că metoda componentelor principale optimizează exact dispersia datelor originale proiectate pe axele pe care le selectează. Dacă componenta principală este corelată cu o axă inițială, componenta și axa pot fi direcționate în aceeași direcție (au o corelație pozitivă) sau în direcții opuse (au corelații negative). Ambele variante sunt echivalente. Algoritmul metodei componentei principale poate sau nu „întoarce” orice plan; nu trebuie trase concluzii din asta.
Cu toate acestea, punctele din fig. 9.1.2 nu sunt pur și simplu „cu susul în jos” în comparație cu pozițiile lor relative din Fig. 9.1.1; Pozițiile lor relative s-au schimbat și ele într-un anumit fel. Diferențele dintre punctele din a doua componentă principală par a fi sporite. 22,76% din variația totală atribuibilă celei de-a doua componente „împrăștie” punctele cu aceeași distanță ca 77,24% din varianța atribuibilă primei componente principale.
Pentru ca localizarea punctelor pe planul componentelor principale să corespundă locației lor reale, acest plan ar trebui să fie distorsionat. În fig. 9.1.3. sunt prezentate două cercuri concentrice; razele lor sunt legate ca părți ale variațiilor reflectate de prima și a doua componentă principală. Imaginea corespunzătoare fig. 9.1.2, distorsionat astfel încât deviație standard după prima componentă principală corespundea unui cerc mai mare, iar după a doua - unuia mai mic.

Orez. 9.1.3. Am avut în vedere că prima componentă principală reprezintă b O o pondere mai mare a varianței decât a doua. Pentru a face acest lucru, am distorsionat figura. 9.1.2, potrivindu-l pe două cercuri concentrice ale căror raze sunt legate ca proporții ale variațiilor atribuibile componentelor principale. Dar locația punctelor încă nu corespunde cu cea originală prezentată în Fig. 9.1.1!
De ce poziția relativă a punctelor din fig. 9.1.3 nu corespunde cu cel din Fig. 9.1.1? În figura originală, Fig. 9.1, punctele sunt situate în conformitate cu coordonatele lor, și nu în conformitate cu cotele de varianță atribuibile fiecărei axe. O distanță de 1 unitate conform primului semn (de-a lungul axei x) din Fig. 9.1.1 există o proporție mai mică a dispersiei punctelor de-a lungul acestei axe decât distanța de 1 unitate conform celei de-a doua caracteristici (de-a lungul ordonatei). Iar în Fig. 9.1.1, distanțele dintre puncte sunt determinate precis de unitățile în care sunt măsurate caracteristicile prin care sunt descrise.
Să complicăm puțin sarcina. În tabel Figura 9.1.1 prezintă coordonatele a 10 puncte din spațiul cu 10 dimensiuni. Primele trei puncte și primele două dimensiuni sunt exemplul pe care tocmai ne-am uitat.
Tabelul 9.1.1. Coordonatele punctelor pentru analize ulterioare
|
Coordonatele |
||||||||||
În scopuri educaționale, vom lua în considerare mai întâi doar o parte din datele din tabel. 9.1.1. În fig. 9.1.4 vedem poziţia a zece puncte pe planul primelor două semne. Vă rugăm să rețineți că prima componentă principală (linia C) a mers puțin diferit față de cazul precedent. Nu e de mirare: poziția sa este influențată de toate punctele luate în considerare.

Orez. 9.1.4. Am mărit numărul de puncte. Prima componentă principală merge puțin diferit, deoarece a fost influențată de punctele adăugate
În fig. Figura 9.1.5 prezintă poziţia celor 10 puncte pe care le-am considerat pe planul primelor două componente. Observați că totul s-a schimbat, nu doar proporția de varianță reprezentată de fiecare componentă principală, ci chiar și poziția primelor trei puncte!

Orez. 9.1.5. Ordonarea în plan a primelor componente principale ale celor 10 puncte descrise în tabel. 9.1.1. Au fost luate în considerare doar valorile primelor două caracteristici, ultimele 8 coloane ale tabelului. 9.1.1 nu au fost utilizate
În general, acest lucru este firesc: deoarece componentele principale sunt situate diferit, pozițiile relative ale punctelor s-au schimbat și ele.
Dificultățile în compararea locației punctelor pe planul componentei principale și pe planul original al valorilor caracteristicilor lor pot provoca confuzie: de ce să folosiți o metodă atât de dificil de interpretat? Răspunsul este simplu. În cazul în care obiectele comparate sunt descrise doar de două caracteristici, este foarte posibil să se folosească hirotonirea lor în funcție de aceste caracteristici inițiale. Toate avantajele metodei componentelor principale apar în cazul datelor multidimensionale. În acest caz, metoda componentei principale se dovedește a fi mod eficient reducerea dimensionalității datelor.
9.2. Trecerea la datele inițiale cu mai multe dimensiuni
Să luăm în considerare un caz mai complex: să analizăm datele prezentate în tabel. 9.1.1 pentru toate cele zece caracteristici. În fig. Figura 9.2.1 arată cum este numită fereastra metodei care ne interesează.

Orez. 9.2.1. Rularea metodei componentelor principale
Ne va interesa doar selectarea caracteristicilor pentru analiză, deși dialogul Statistica permite o reglare mult mai fină (Fig. 9.2.2).

Orez. 9.2.2. Selectarea variabilelor pentru analiză
După efectuarea analizei, apare o fereastră cu rezultatele acesteia cu mai multe file (Fig. 9.2.3). Toate ferestrele principale sunt accesibile din prima filă.

Orez. 9.2.3. Prima filă din dialogul cu rezultatele analizei componentelor principale
Puteți observa că analiza a identificat 9 componente principale și, cu ajutorul lor, a descris 100% din varianța reflectată în cele 10 caracteristici inițiale. Aceasta înseamnă că un semn era de prisos, redundant.
Să începem vizualizarea rezultatelor cu butonul „Plot case factor voordinates, 2D”: va afișa locația punctelor pe planul definit de cele două componente principale. Făcând clic pe acest buton, vom fi duși la un dialog în care va trebui să indicăm ce componente vom folosi; Este firesc să începem analiza cu prima și a doua componentă. Rezultatul este prezentat în Fig. 9.2.4.

Orez. 9.2.4. Ordonarea obiectelor luate în considerare pe planul primelor două componente principale
Poziția punctelor s-a schimbat, iar acest lucru este firesc: noi caracteristici sunt implicate în analiză. În fig. 9.2.4 reflectă mai mult de 65% din diversitatea totală în poziția punctelor unul față de celălalt, iar acesta este deja un rezultat netrivial. De exemplu, revenirea la masă. 9.1.1, puteți verifica că punctele 4 și 7, precum și 8 și 10, sunt într-adevăr destul de aproape unul de celălalt. Cu toate acestea, diferențele dintre ele pot viza și alte componente principale care nu sunt prezentate în figură: ele, la urma urmei, reprezintă și o treime din variabilitatea rămasă.
Apropo, atunci când se analizează plasarea punctelor pe planul componentelor principale, poate fi necesar să se analizeze distanțele dintre ele. Cel mai simplu mod de a obține o matrice a distanțelor dintre puncte este utilizarea unui modul pentru analiza cluster.
Cum sunt componentele principale identificate legate de caracteristicile originale? Acest lucru poate fi aflat făcând clic pe butonul (Fig. 9.2.3) Plot var. coordonate factori, 2D. Rezultatul este prezentat în Fig. 9.2.5.

Orez. 9.2.5. Proiecții ale caracteristicilor originale pe planul primelor două componente principale
Ne uităm la planul celor două componente principale „de sus”. Caracteristicile inițiale, care nu au nicio legătură cu componentele principale, vor fi perpendiculare (sau aproape perpendiculare) pe acestea și se vor reflecta în segmente scurte care se termină în apropierea originii coordonatelor. Astfel, trăsătura nr. 6 este cel mai puțin asociată cu primele două componente principale (deși demonstrează o anumită corelație pozitivă cu prima componentă). Segmentele corespunzătoare acelor trăsături care se reflectă complet pe planul componentelor principale se vor termina pe un cerc de rază unitară care înconjoară centrul figurii.
De exemplu, puteți vedea că prima componentă principală a fost cel mai puternic influențată de caracteristicile 10 (corelate pozitiv), precum și de 7 și 8 (corelate negativ). Pentru a analiza mai detaliat structura unor astfel de corelații, puteți face clic pe butonul Coordonatele factorilor variabile și puteți obține tabelul prezentat în Fig. 9.2.6.

Orez. 9.2.6. Corelații între caracteristicile inițiale și componentele principale identificate (factori)
Butonul Eigenvalues afișează valorile numite valorile proprii ale principalelor componente. În partea de sus a ferestrei prezentate în fig. 9.2.3, următoarele valori sunt afișate pentru primele câteva componente; Butonul Scree plot le arată într-o formă ușor de citit (Fig. 9.2.7).

Orez. 9.2.7. Valorile proprii ale componentelor principale identificate și ponderea varianței totale reflectată de acestea
Mai întâi trebuie să înțelegeți ce arată exact valoarea proprie. Aceasta este o măsură a varianței reflectate în componenta principală, măsurată în cantitatea de varianță reprezentată de fiecare caracteristică din datele inițiale. Dacă valoarea proprie a primei componente principale este 3,4, aceasta înseamnă că aceasta reprezintă mai multă varianță decât cele trei caracteristici din setul inițial. Valorile proprii sunt legate liniar de cota de varianță atribuită componentei principale; singurul lucru este că suma valorilor proprii este egală cu numărul de caracteristici originale, iar suma cotelor de varianță este egală cu 100% .
Ce înseamnă că informațiile despre variabilitate pentru 10 caracteristici au fost reflectate în 9 componente principale? Faptul că una dintre caracteristicile inițiale era redundantă nu a adăugat nicio informație nouă. Și așa a fost; în fig. 9.2.8 arată cum a fost generat setul de puncte reflectat în tabel. 9.1.1.
Metoda componentelor principale(PCA - Analiza componentelor principale) este una dintre principalele modalități de reducere a dimensiunii datelor cu pierderi minime de informații. Inventat în 1901 de Karl Pearson, este utilizat pe scară largă în multe domenii. De exemplu, pentru compresia datelor, „viziunea pe computer”, recunoașterea imaginilor vizibile etc. Calculul componentelor principale se reduce la calcularea vectorilor proprii și a valorilor proprii ale matricei de covarianță a datelor originale. Metoda componentei principale este adesea numită Transformarea Karhunen-Löwe(transformarea Karhunen-Loeve) sau Transformarea hotelierei(Transformarea hotelieră). La această problemă au lucrat și matematicienii Kosambi (1943), Pugaciov (1953) și Obukhova (1954).
Sarcina analizei componentelor principale urmărește aproximarea (apropierea) datelor prin varietăți liniare de dimensiune inferioară; găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care răspândirea datelor (adică abaterea standard de la valoarea medie) este maximă; găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care distanța pătratică medie dintre puncte este maximă. În acest caz, ele operează cu seturi finite de date. Sunt echivalente și nu folosesc nicio ipoteză despre generarea statistică a datelor.
În plus, sarcina analizei componentelor principale poate fi de a construi pentru o variabilă aleatoare multidimensională dată o astfel de transformare ortogonală a coordonatelor, încât, ca urmare, corelațiile dintre coordonatele individuale să devină zero. Această versiune funcționează variabile aleatoare.
Fig.3
Figura de mai sus arată punctele P i pe plan, p i este distanța de la P i la dreapta AB. Căutăm o linie dreaptă AB care minimizează suma
Metoda componentelor principale a început cu problema celei mai bune aproximări (aproximații) a unui set finit de puncte prin linii drepte și plane. De exemplu, dat un set finit de vectori. Pentru fiecare k = 0,1,...,n? 1 dintre toate varietățile liniare k-dimensionale în găsiți astfel încât suma abaterilor pătrate x i de la L k este minimă:
Unde? Distanța euclidiană de la un punct la o varietate liniară.
Orice varietate liniară k-dimensională în poate fi definită ca un set de combinații liniare, unde parametrii din i se desfășoară de-a lungul liniei reale, nu? set ortonormal de vectori
unde este norma euclidiană? Produs punctual euclidian sau sub formă de coordonate:
Rezolvarea problemei de aproximare pentru k = 0,1,...,n? 1 este dat de un set de varietati liniare imbricate
Aceste varietăți liniare sunt definite de o mulțime ortonormală de vectori (vectori componente principale) și un vector a 0 . Se caută vectorul a 0 ca soluție la problema de minimizare pentru L 0:


Rezultatul este o medie de probă:
Matematician francez Maurice Fréchet Fréchet Maurice René (09/02/1878 - 06/04/1973) - un matematician francez remarcabil. A lucrat în domeniul topologiei și analizei funcționale, teoria probabilității. Autor concepte moderne pe spațiu metric, compactitate și completitudine. Auto. în 1948, el a observat că definiția variațională a mediei, ca punct care minimizează suma distanțelor pătrate la punctele de date, este foarte convenabilă pentru a construi statistici într-un spațiu metric arbitrar și a construit o generalizare a statisticilor clasice pentru spațiile generale. , numită metoda generalizată a celor mai mici pătrate.
Vectorii componentelor principale pot fi găsiți ca soluții la probleme similare de optimizare:
1) centralizați datele (scădeți media):
2) găsiți prima componentă principală ca soluție a problemei;

3) Scădeți proiecția pe prima componentă principală din date:
4) găsiți a doua componentă principală ca soluție a problemei

Dacă soluția nu este unică, atunci alegeți una dintre ele.
2k-1) Scădeți proiecția pe (k ? 1)-a componentă principală (amintim că proiecțiile asupra componentelor principale anterioare (k ? 2) au fost deja scăzute):
2k) găsiți a k-a componentă principală ca soluție a problemei:

Dacă soluția nu este unică, atunci alegeți una dintre ele.

Orez. 4
Prima componentă principală maximizează varianța eșantionului a proiecției datelor.
De exemplu, să ni se dea un set centrat de vectori de date în care media aritmetică x i este zero. Sarcină? găsiți o transformare ortogonală într-un nou sistem de coordonate pentru care următoarele condiții ar fi adevărate:
1. Varianta eșantionului de date de-a lungul primei coordonate (componenta principală) este maximă;
2. Dispersia eșantionului de date de-a lungul celei de-a doua coordonate (a doua componentă principală) este maximă în condițiile ortogonalității față de prima coordonată;
3. Dispersia eșantionului de date de-a lungul valorilor coordonatei k-a este maximă în condițiile ortogonalității cu primul k? 1 coordonate;
Varianta eșantionului de date de-a lungul direcției specificate de vectorul normalizat a k este
(Deoarece datele sunt centrate, varianța eșantionului aici este aceeași cu pătratul mediu al abaterii de la zero).
Rezolvarea problemei celei mai bune potriviri oferă același set de componente principale ca și găsirea proiecțiilor ortogonale cu cea mai mare împrăștiere, dintr-un motiv foarte simplu:
iar primul termen nu depinde de un k.
Matricea de transformare a datelor în componentele principale este construită din vectorii „A” ai componentelor principale:
Aici ai sunt vectori coloană ortonormali ai componentelor principale, aranjați în ordinea descrescătoare a valorilor proprii, superscriptul T înseamnă transpunere. Matricea A este ortogonală: AA T = 1.
După transformare, cea mai mare parte a variației datelor va fi concentrată în primele coordonate, ceea ce face posibilă eliminarea celor rămase și luarea în considerare a unui spațiu cu dimensiuni reduse.
Cea mai veche metodă de selectare a componentelor principale este regula Kaiser, Kaiser Johann Henrich Gustav (16.03.1853, Brezno, Prusia - 14.10.1940, Germania) - un remarcabil matematician, fizician, cercetător în domeniul analizei spectrale. Auto. conform căreia acele componente principale pentru care sunt semnificative
adică l i depășește valoarea medie l (varianța medie a eșantionului a coordonatelor vectorului de date). Regula Kaiser funcționează bine în cazuri simple, când există mai multe componente principale cu l i mult mai mare decât valoarea medie, iar valorile proprii rămase sunt mai mici decât aceasta. În cazuri mai complexe, poate produce prea multe componente principale semnificative. Dacă datele sunt normalizate la variația eșantionului unitar de-a lungul axelor, atunci regula lui Kaiser ia o formă deosebit de simplă: numai acele componente principale pentru care l i > 1 sunt semnificative.
Una dintre cele mai populare abordări euristice pentru estimarea numărului de componente principale necesare este regula bastonului rupt, când setul este normalizat la o sumă unitară valori proprii(, i = 1,...n) se compară cu distribuția lungimilor fragmentelor unui baston de lungime unitară rupte la n ? Primul punct selectat aleatoriu (punctele de rupere sunt selectate independent și distribuite egal pe lungimea bastonului). Dacă L i (i = 1,...n) sunt lungimile pieselor de trestie rezultate, numerotate în ordinea descrescătoare a lungimii: , atunci așteptarea matematică a lui L i:

Să ne uităm la un exemplu care implică estimarea numărului de componente principale folosind regula bastonului rupt în dimensiunea 5.

Orez. 5.
Conform k-a regula bastonului rupt vector propriu(în ordinea descrescătoare a valorilor proprii l i) este stocată în lista componentelor principale dacă
Figura de mai sus prezintă un exemplu pentru cazul cu 5 dimensiuni:
l 1 =(1+1/2+1/3+1/4+1/5)/5; l 2 =(1/2+1/3+1/4+1/5)/5; l 3 =(1/3+1/4+1/5)/5;
l 4 =(1/4+1/5)/5; l 5 =(1/5)/5.
De exemplu, selectat
0.5; =0.3; =0.1; =0.06; =0.04.
Conform regulii bastonului rupt, în acest exemplu ar trebui să lăsați 2 componente principale:
Un lucru de reținut este că regula bastonului rupt tinde să subestimeze numărul de componente principale semnificative.
După proiectarea pe primele k componente principale c, este convenabil să se normalizeze la varianța unitară (eșantionului) de-a lungul axelor. Dispersia de-a lungul celei de-a i-a componente principale este egală cu), deci pentru normalizare este necesară împărțirea coordonatei corespunzătoare la. Această transformare nu este ortogonală și nu păstrează produsul punctual. Matricea de covarianță a proiecției datelor după normalizare devine unitate, proiecțiile către oricare două direcții ortogonale devin mărimi independente și orice bază ortonormală devine baza componentelor principale (amintim că normalizarea modifică relația de ortogonalitate a vectorilor). Maparea din spațiul de date sursă la primele k componente principale, împreună cu normalizarea, este specificată de matrice

Această transformare este cea mai adesea numită transformarea Karhunen-Loeve, adică metoda componentei principale în sine. Aici a i sunt vectori coloană, iar superscriptul T înseamnă transpunere.
În statistică, atunci când se utilizează metoda componentelor principale, se folosesc mai mulți termeni speciali.
Data Matrix, unde fiecare rând este un vector de date preprocesate (centrate și normalizate corect), numărul de rânduri este m (numărul de vectori de date), numărul de coloane este n (dimensiunea spațiului de date);
Matricea de încărcare(Încărcări), unde fiecare coloană este un vector de componentă principală, numărul de rânduri este n (dimensiunea spațiului de date), numărul de coloane este k (numărul de vectori de componentă principală selectați pentru proiecție);
Matricea contului(Scoruri)
unde fiecare linie este proiecția vectorului de date pe k componente principale; numărul de rânduri - m (numărul de vectori de date), numărul de coloane - k (numărul de vectori de componente principale selectați pentru proiecție);
Matricea scorului Z(scoruri Z)

unde fiecare rând este o proiecție a vectorului de date pe k componente principale, normalizate la varianța eșantionului unitar; numărul de rânduri - m (numărul de vectori de date), numărul de coloane - k (numărul de vectori de componente principale selectați pentru proiecție);
Matricea erorilor (resturi) (Erori sau reziduuri)
Formula de baza:
Astfel, Metoda componentei principale este una dintre principalele metode de statistică matematică. Scopul său principal este de a face distincția între necesitatea de a studia seturile de date cu un minim de utilizare a acestora.
Punctul de plecare pentru analiză este matricea de date
dimensiuni  , al cărui rând i-a caracterizează i-a observație (obiect) pentru toți k indicatori
, al cărui rând i-a caracterizează i-a observație (obiect) pentru toți k indicatori  . Datele sursă sunt normalizate, pentru care se calculează valorile medii ale indicatorilor
. Datele sursă sunt normalizate, pentru care se calculează valorile medii ale indicatorilor  , precum și valorile deviației standard
, precum și valorile deviației standard  . Apoi matricea valorilor normalizate
. Apoi matricea valorilor normalizate

cu elemente 
Se calculează matricea coeficienților de corelație de perechi:

Elementele unității sunt situate pe diagonala principală a matricei  .
.
Modelul de analiză a componentelor este construit prin reprezentarea datelor normalizate originale ca o combinație liniară a componentelor principale:

Unde  - „greutate”, adică încărcarea factorilor
- „greutate”, adică încărcarea factorilor 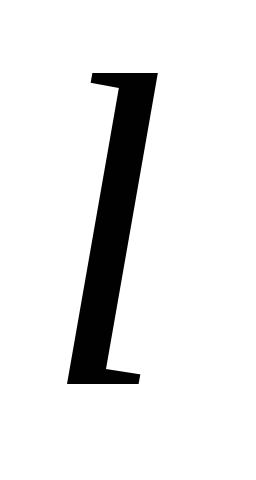 componenta principală activată
componenta principală activată  -a variabila;
-a variabila;
 -sens
-sens  componenta principală pentru
componenta principală pentru  -observare (obiect), unde
-observare (obiect), unde  .
.
În formă de matrice, modelul are forma

Aici  - matricea componentelor principale ale dimensiunii
- matricea componentelor principale ale dimensiunii  ,
,
 - matricea încărcărilor factoriale de aceeași dimensiune.
- matricea încărcărilor factoriale de aceeași dimensiune.
Matrice  descrie
descrie  observatii in spatiu
observatii in spatiu  componentele principale. În acest caz, elementele matricei
componentele principale. În acest caz, elementele matricei  sunt normalizate, iar componentele principale nu sunt corelate între ele. Rezultă că
sunt normalizate, iar componentele principale nu sunt corelate între ele. Rezultă că 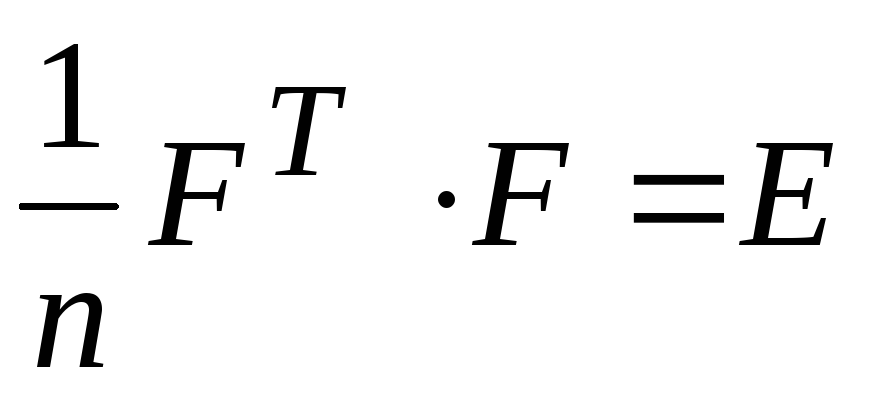 , Unde
, Unde  – matricea unitară a dimensiunii
– matricea unitară a dimensiunii  .
.
Element  matrici
matrici  caracterizează apropierea relaţiei liniare dintre variabila iniţială
caracterizează apropierea relaţiei liniare dintre variabila iniţială  și componenta principală
și componenta principală  , prin urmare, ia valorile
, prin urmare, ia valorile  .
.
Matricea de corelație  poate fi exprimat printr-o matrice de încărcări factoriale
poate fi exprimat printr-o matrice de încărcări factoriale  .
.
Unitățile sunt situate de-a lungul diagonalei principale a matricei de corelație și, prin analogie cu matricea de covarianță, ele reprezintă variațiile matricei utilizate  -caracteristici, dar spre deosebire de acestea din urma, datorita normalizarii, aceste variatii sunt egale cu 1. Varianta totala a intregului sistem
-caracteristici, dar spre deosebire de acestea din urma, datorita normalizarii, aceste variatii sunt egale cu 1. Varianta totala a intregului sistem  -caracteristici ale volumului probei
-caracteristici ale volumului probei  egală cu suma acestor unități, adică egală cu urma matricei de corelaţie
egală cu suma acestor unități, adică egală cu urma matricei de corelaţie  .
.
Matricea de corelație poate fi transformată într-o matrice diagonală, adică o matrice ale cărei toate valorile, cu excepția celor diagonale, sunt egale cu zero:
 ,
,
Unde  - o matrice diagonală pe a cărei diagonală principală există valori proprii
- o matrice diagonală pe a cărei diagonală principală există valori proprii  matricea de corelatie,
matricea de corelatie,  - o matrice ale cărei coloane sunt vectori proprii ai matricei de corelație
- o matrice ale cărei coloane sunt vectori proprii ai matricei de corelație  . Deoarece matricea R este definită pozitiv, i.e. minorii săi conducători sunt pozitivi, apoi toate valorile proprii
. Deoarece matricea R este definită pozitiv, i.e. minorii săi conducători sunt pozitivi, apoi toate valorile proprii  pentru orice
pentru orice  .
.
Valori proprii  se găsesc ca rădăcini ale ecuaţiei caracteristice
se găsesc ca rădăcini ale ecuaţiei caracteristice

Vector propriu  , corespunzătoare valorii proprii
, corespunzătoare valorii proprii  matricea de corelare
matricea de corelare  , este definită ca o soluție diferită de zero a ecuației
, este definită ca o soluție diferită de zero a ecuației

Vector propriu normalizat  egală
egală

Dispariția termenilor non-diagonali înseamnă că caracteristicile devin independente unele de altele ( 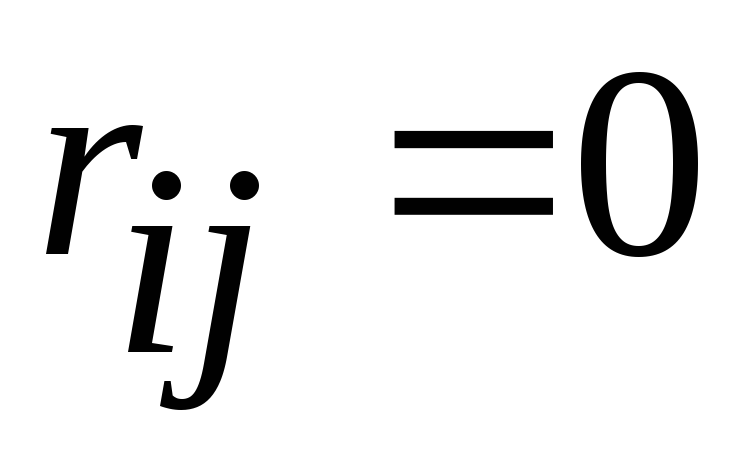 la
la  ).
).
Varianta totala a intregului sistem  variabilele din populația eșantionului rămân aceleași. Cu toate acestea, valorile sale sunt redistribuite. Procedura pentru găsirea valorilor acestor varianțe este găsirea valorilor proprii
variabilele din populația eșantionului rămân aceleași. Cu toate acestea, valorile sale sunt redistribuite. Procedura pentru găsirea valorilor acestor varianțe este găsirea valorilor proprii  matricea de corelație pentru fiecare dintre
matricea de corelație pentru fiecare dintre 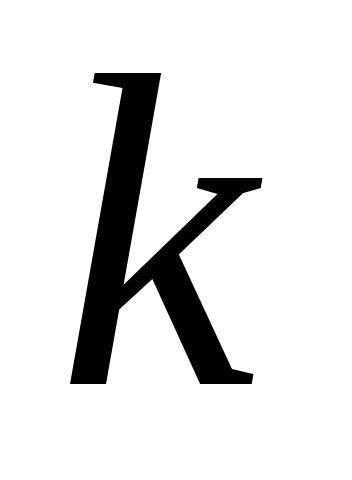 -semne. Suma acestor valori proprii
-semne. Suma acestor valori proprii  este egală cu urma matricei de corelație, i.e.
este egală cu urma matricei de corelație, i.e.  , adică numărul de variabile. Aceste valori proprii sunt valorile de varianță ale caracteristicilor
, adică numărul de variabile. Aceste valori proprii sunt valorile de varianță ale caracteristicilor  în condiţiile în care semnele ar fi independente unele de altele.
în condiţiile în care semnele ar fi independente unele de altele.
În metoda componentelor principale, o matrice de corelație este mai întâi calculată din datele originale. Apoi se transformă ortogonal și prin aceasta se găsesc încărcările factorilor  pentru toți
pentru toți 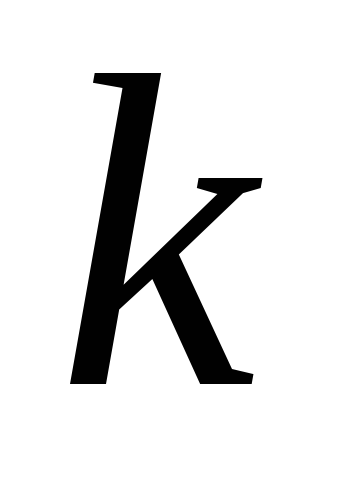 variabile şi
variabile şi  factori (matricea încărcărilor factorilor), valori proprii
factori (matricea încărcărilor factorilor), valori proprii  și determinați ponderile factorilor.
și determinați ponderile factorilor.
Matricea de încărcare a factorilor A poate fi definită ca 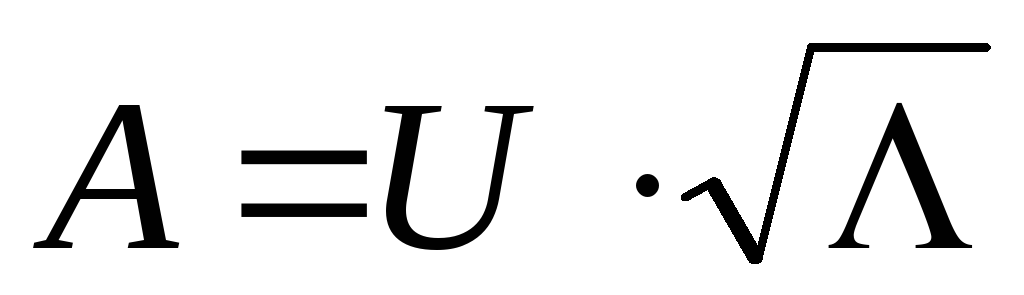 , A
, A  a-a coloană a matricei A - cum
a-a coloană a matricei A - cum  .
.
Ponderea factorilor  sau
sau  reflectă ponderea din variația totală contribuită de acest factor.
reflectă ponderea din variația totală contribuită de acest factor.
Încărcările factorilor variază de la –1 la +1 și sunt analoge cu coeficienții de corelație. În matricea de încărcare a factorilor, este necesar să se identifice încărcările semnificative și nesemnificative folosind testul t Student.  .
.
Suma încărcărilor pătrate  - al-lea factor în total
- al-lea factor în total  -caracteristicile este egală cu valoarea proprie a unui factor dat
-caracteristicile este egală cu valoarea proprie a unui factor dat  . Apoi
. Apoi  -contribuția variabilei i-a în % la formarea factorului j-lea.
-contribuția variabilei i-a în % la formarea factorului j-lea.
Suma pătratelor tuturor încărcărilor de factori pentru un rând este egală cu unu, varianța totală a unei variabile și a tuturor factorilor pentru toate variabilele este egală cu varianța totală (adică, urma sau ordinea matricei de corelație, sau suma valorilor sale proprii)  .
.
În general, structura factorială a atributului i-lea este prezentată sub formă  , care include doar sarcini semnificative. Folosind matricea încărcărilor factorilor, puteți calcula valorile tuturor factorilor pentru fiecare observație a populației eșantionului inițial folosind formula:
, care include doar sarcini semnificative. Folosind matricea încărcărilor factorilor, puteți calcula valorile tuturor factorilor pentru fiecare observație a populației eșantionului inițial folosind formula:
 ,
,
Unde  – valoarea factorului j-a pentru a-a-a observație,
– valoarea factorului j-a pentru a-a-a observație,  -valoarea standardizată a i-a trăsătură a observației a-a a eșantionului original;
-valoarea standardizată a i-a trăsătură a observației a-a a eșantionului original;  - sarcina factoriala,
- sarcina factoriala,  – valoarea proprie corespunzătoare factorului j. Aceste valori calculate
– valoarea proprie corespunzătoare factorului j. Aceste valori calculate  sunt utilizate pe scară largă pentru a reprezenta grafic rezultatele analizei factoriale.
sunt utilizate pe scară largă pentru a reprezenta grafic rezultatele analizei factoriale.
Folosind matricea încărcărilor factorilor, matricea de corelație poate fi reconstruită:  .
.
Porțiunea de varianță a unei variabile explicată de componentele principale se numește comunalitate
 ,
,
Unde  - număr variabil și
- număr variabil și  - numărul componentei principale. Coeficienții de corelație restabiliți numai din componentele principale vor fi mai mici decât cei inițiali în valoare absolută, iar pe diagonală nu vor fi 1, ci valorile generalităților.
- numărul componentei principale. Coeficienții de corelație restabiliți numai din componentele principale vor fi mai mici decât cei inițiali în valoare absolută, iar pe diagonală nu vor fi 1, ci valorile generalităților.
Contribuție specifică  - componenta principală este determinată de formulă
- componenta principală este determinată de formulă
 .
.
Contribuția totală a contabilității 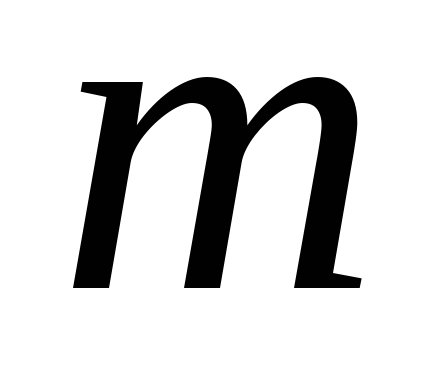 componentele principale sunt determinate din expresie
componentele principale sunt determinate din expresie
 .
.
Folosit de obicei pentru analiză 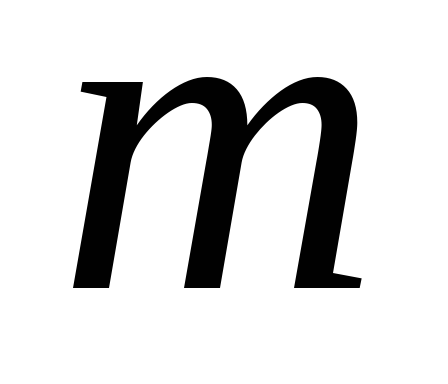 primele componente principale, a căror contribuție la varianța totală depășește 60-70%.
primele componente principale, a căror contribuție la varianța totală depășește 60-70%.
Matricea de încărcare a factorilor A este utilizată pentru a interpreta componentele principale, luând în considerare de obicei acele valori mai mari de 0,5.
Valorile componentelor principale sunt specificate de matrice

Componentele principale
5.1 Metode regresie multiplă iar corelația canonică implică împărțirea setului existent de caracteristici în două părți. Cu toate acestea, o astfel de diviziune poate să nu fie întotdeauna întemeiată în mod obiectiv și, prin urmare, este nevoie de abordări de analiză a relațiilor dintre indicatori care ar implica luarea în considerare a vectorului caracteristicilor ca un întreg. Desigur, la implementarea unor astfel de abordări, o anumită eterogenitate poate fi detectată în această baterie de caracteristici atunci când sunt identificate obiectiv mai multe grupuri de variabile. Pentru caracteristicile dintr-un astfel de grup, corelațiile încrucișate vor fi mult mai mari în comparație cu combinațiile de indicatori din grupuri diferite. Totuși, această grupare se va baza pe rezultatele unei analize obiective a datelor, și nu pe considerentele arbitrare a priori ale cercetătorului.
5.2 Când studiem corelațiile în cadrul unui singur set de m caracteristici
X„= X 1 X 2 X 3 ... X m
puteți folosi aceeași metodă care a fost folosită în analiza regresiei multiple și metoda corelațiilor canonice - obținerea de noi variabile, a căror variație reflectă pe deplin existența corelațiilor multivariate.
Scopul luării în considerare a conexiunilor intragrup ale unui singur set de caracteristici este de a determina și reprezenta vizual direcțiile principale existente în mod obiectiv ale variației relative a acestor variabile. Prin urmare, în aceste scopuri, puteți introduce câteva variabile noi Y i , găsite ca combinații liniare ale setului original de caracteristici X
Y 1 = b 1"X= b 11 X 1 + b 12 X 2 + b 13 X 3 + ... + b 1m X m
Y2= b 2"X= b 21 X 1 + b 22 X 2 + b 23 X 3 + ... + b 2m X m
Y 3 = b 3"X= b 31 X 1 + b 32 X 2 + b 33 X 3 + ... + b 3m X m (5.1)
... ... ... ... ... ... ...
Y m = b m „X= b m1 X 1 + b m2 X 2 + b m3 X 3 + ... + b m m X m
și având o serie de proprietăți dezirabile. Pentru certitudine, numărul de caracteristici noi să fie egal cu numărul de caracteristici originale (m).
Una dintre aceste proprietăți optime de dorit poate fi necorelarea reciprocă a noilor variabile, adică forma diagonală a matricei lor de covarianță
S y1 2 0 0 ... 0
0 s y2 2 0 ... 0
S y= 0 0 s y3 2 ... 0 , (5.2)
... ... ... ... ...
0 0 0 … s ym 2
unde s yi 2 este varianța i-a nouă caracteristică Y i. Necorelarea noilor variabile, pe lângă comoditatea sa evidentă, are o proprietate importantă - fiecare caracteristică nouă Y i va lua în considerare doar partea sa independentă a informațiilor despre variabilitatea și corelarea indicatorilor originali X.
A doua proprietate necesară a noilor caracteristici este contabilizarea ordonată a variațiilor indicatorilor originali. Astfel, prima variabilă nouă Y 1 să ia în considerare ponderea maximă a variației totale a trăsăturilor X. Aceasta, așa cum vom vedea mai târziu, este echivalentă cu cerința ca Y 1 să aibă variația maximă posibilă s y1 2. Ținând cont de egalitatea (1.17), această condiție poate fi scrisă sub forma
s y1 2 = b 1 "Sb 1= max , (5,3)
Unde S- matricea de covarianță a caracteristicilor inițiale X, b 1- un vector care include coeficienții b 11, b 12, b 13, ..., b 1m cu ajutorul căruia, din valorile lui X 1, X 2, X 3, ..., X m, valoarea de Y 1 poate fi obținut.
Fie a doua nouă variabilă Y 2 să descrie partea maximă a acelei componente a variației totale care rămâne după luarea în considerare a ponderii sale cele mai mari în variabilitatea primei caracteristici noi Y 1 . Pentru a realiza acest lucru, condiția trebuie îndeplinită
s y2 2 = b 2 "Sb 2= max , (5,4)
la zero conexiunea Y 1 cu Y 2, (adică r y1y2 = 0) și la s y1 2 > s y2 2.
În mod similar, a treia caracteristică nouă Y 3 ar trebui să descrie a treia cea mai importantă parte a variației caracteristicilor originale, pentru care varianța sa ar trebui să fie, de asemenea, maximă.
s y3 2 = b 3 "Sb 3= max , (5,5)
în condițiile în care Y 3 este necorelat cu primele două caracteristici noi Y 1 și Y 2 (adică r y1y3 = 0, r y2y3 = 0) și s y1 2 > s y2 > s y3 2 .
Astfel, varianțele tuturor noilor variabile sunt caracterizate prin ordonarea în mărime
s y1 2 > s y2 2 > s y3 2 > ... > s y m 2 . (5,6)
5.3 Vectori din formula (5.1) b 1 , b 2 , b 3 , ..., b m , cu ajutorul căruia ar trebui efectuată trecerea la noile variabile Y i, poate fi scris sub forma unei matrice
B = b 1 b 2 b 3 ... b m. (5,7)
Tranziția de la un set de caracteristici inițiale X la un set de variabile noi Y poate fi reprezentat ca o formulă matriceală
Y = B" X , (5.8)
și obținerea unei matrice de covarianță a noilor caracteristici și realizarea condiției (5.2) de necorelare a noilor variabile în conformitate cu formula (1.19) poate fi reprezentată ca
B"SB= S y , (5.9)
unde este matricea de covarianță a noilor variabile S y datorita naturii lor necorelate, are forma diagonala. Din teoria matricelor (secțiunea A.25 Anexa A) se știe că, obținându-se pentru o matrice simetrică A vectori proprii tu iși numerele l i și invers
chemând matrici din ele UȘi L, conform formulei (A.31) putem obține rezultatul
U"AU= L ,
Unde L- matrice diagonală care include valorile proprii ale unei matrice simetrice A. Este ușor de observat că ultima egalitate coincide complet cu formula (5.9). Prin urmare, putem trage următoarea concluzie. Proprietățile de dorit ale noilor variabile Y pot fi furnizate dacă vectorii b 1 , b 2 , b 3 , ..., b m , cu ajutorul căruia ar trebui efectuată tranziția la aceste variabile, vor fi vectorii proprii ai matricei de covarianță a caracteristicilor originale S. Apoi, variațiile noilor caracteristici s yi 2 se vor dovedi a fi valori proprii
s y1 2 = l 1, s y2 2 = l 2, s y3 2 = l 3, ..., s ym 2 = l m (5.10)
Variabilele noi, tranziția la care conform formulelor (5.1) și (5.8) se realizează folosind vectorii proprii ai matricei de covarianță a caracteristicilor originale, sunt numite componente principale. Datorită faptului că numărul de vectori proprii ai matricei de covarianță în caz general este egal cu m - numărul de caracteristici inițiale pentru această matrice, numărul de componente principale este de asemenea egal cu m.
În conformitate cu teoria matricei, pentru a găsi valorile proprii și vectorii matricei de covarianță, ar trebui să rezolvăm ecuația
(S-l eu eu)b eu = 0 . (5.11)
Această ecuație are o soluție dacă este îndeplinită condiția ca determinantul să fie egal cu zero
½ S-l eu eu½ = 0. (5,12)
Această condiție se dovedește, de asemenea, a fi o ecuație ale cărei rădăcini sunt toate valorile proprii l 1 , l 2 , l 3 , ..., l m ale matricei de covarianță care coincid simultan cu variațiile componentelor principale. După obținerea acestor numere, pentru fiecare i-a dintre ele, folosind ecuația (5.11), puteți obține vectorul propriu corespunzător b i. În practică, procedurile speciale de iterație sunt utilizate pentru a calcula valorile proprii și vectorii (Anexa B).
Toți vectorii proprii pot fi scriși ca o matrice B, care va fi o matrice ortonormală, deci (secțiunea A.24 Anexa A) este îndeplinită pentru aceasta
B"B = BB" = eu . (5.13)
Acesta din urmă înseamnă că pentru orice pereche de vectori proprii b i "b j= 0, iar pentru orice astfel de vector egalitatea b i "b i = 1.
5.4 Să ilustrăm derivarea componentelor principale pentru cel mai simplu caz a două caracteristici inițiale X 1 și X 2 . Matricea de covarianță pentru această mulțime este
unde s 1 și s 2 sunt abaterile standard ale caracteristicilor X 1 și X 2, iar r este coeficientul de corelație dintre ele. Atunci condiția (5.12) poate fi scrisă sub forma
S 1 2 - l i rs 1 s 2
rs 1 s 2 s 2 2 - l i

Figura 5.1.Semnificaţia geometrică a principalelor componente
Extinderea determinantului, putem obține ecuația
l 2 - l(s 1 2 + s 2 2) + s 1 2 s 2 2 (1 - r 2) = 0,
Rezolvând care, puteți obține două rădăcini l 1 și l 2. Ecuația (5.11) poate fi scrisă și ca
s 1 2 - l i r s 1 s 2 b i1 = 0
r s 1 s 2 s 2 2 - l i b i2 0
Substituind l 1 în această ecuație, obținem un sistem liniar
(s 1 2 - l 1) b 11 + rs 1 s 2 b 12 = 0
rs 1 s 2 b 11 + (s 2 2 - l 1)b 12 = 0,
a cărui soluție sunt elementele primului vector propriu b 11 și b 12. După o înlocuire similară a celei de-a doua rădăcini l 2, găsim elementele celui de-al doilea vector propriu b 21 și b 22.
5.5 Să aflăm sens geometric componentele principale. Acest lucru se poate face în mod clar doar pentru cel mai simplu caz dintre două caracteristici X 1 și X 2. Să fie caracterizate printr-o distribuție normală bivariată cu un coeficient de corelație pozitiv. Dacă toate observațiile individuale sunt reprezentate pe un plan, format din axe semne, atunci punctele corespunzătoare vor fi situate în interiorul unei anumite elipse de corelație (Fig. 5.1). Caracteristicile noi Y 1 și Y 2 pot fi, de asemenea, descrise pe același plan sub forma de noi axe. Conform sensului metodei, pentru prima componentă principală Y 1, care ia în considerare dispersia totală maximă posibilă a caracteristicilor X 1 și X 2, trebuie atins maximul dispersiei sale. Aceasta înseamnă că pentru Y 1 ar trebui să se găsească
care axă, astfel încât lățimea distribuției valorilor sale să fie cea mai mare. Evident, acest lucru se va realiza dacă această axă coincide în direcție cu cea mai mare axă a elipsei de corelație. Într-adevăr, dacă proiectăm toate punctele corespunzătoare observațiilor individuale pe această coordonată, vom obține o distribuție normală cu intervalul maxim posibil și cea mai mare dispersie. Aceasta va fi distribuția valorilor individuale ale primei componente principale Y 1 .
Axa corespunzătoare celei de-a doua componente principale Y 2 trebuie trasată perpendicular pe prima axă, deoarece aceasta rezultă din condiția ca componentele principale să nu fie corelate. Într-adevăr, în acest caz vom obține un nou sistem de coordonate cu axele Y 1 și Y 2 care coincid în direcția cu axele elipsei de corelație. Se poate observa că elipsa de corelație, atunci când este examinată în noul sistem de coordonate, demonstrează necorelarea valorilor individuale ale Y 1 și Y 2, în timp ce pentru valorile caracteristicilor originale X 1 și X 2 o corelație a fost observat.
Trecerea de la axele asociate caracteristicilor originale X 1 și X 2 la un nou sistem de coordonate orientat către componentele principale Y 1 și Y 2 este echivalentă cu rotirea axelor vechi cu un anumit unghi j. Valoarea acestuia poate fi găsită folosind formula
Tg 2j = . (5,14)
Trecerea de la valorile caracteristicilor X 1 și X 2 la componentele principale poate fi efectuată în conformitate cu rezultatele geometriei analitice sub forma
Y 1 = X 1 cos j + X 2 sin j
Y 2 = - X 1 sin j + X 2 cos j.
Același rezultat poate fi scris sub formă de matrice
Y 1 = cos j sin j X 1 și Y 2 = -sin j cos j X 1,
care corespunde exact transformării Y 1 = b 1"Xși Y2 = b 2"X. Cu alte cuvinte,
= B" . (5.15)
Astfel, matricea vectorului propriu poate fi interpretată și ca incluzând funcții trigonometrice ale unghiului de rotație care trebuie făcute pentru a trece de la sistemul de coordonate asociat caracteristicilor originale la noi axe bazate pe componentele principale.
Dacă avem m caracteristici inițiale X 1, X 2, X 3, ..., X m, atunci observațiile care alcătuiesc eșantionul luat în considerare vor fi localizate în interiorul unui elipsoid de corelație m-dimensional. Apoi, axa primei componente principale va coincide în direcție cu cea mai mare axă a acestui elipsoid, axa celei de-a doua componente principale cu cea de-a doua axă a acestui elipsoid etc. Trecerea de la sistemul de coordonate original asociat cu axele caracteristice X 1, X 2, X 3, ..., X m la noile axe ale componentelor principale va fi echivalentă cu mai multe rotații ale vechilor axe la unghiurile j 1, j 2, j 3, .. . și matricea de tranziție B din platou X la sistemul de componente principale Y, constând din propriile pleoape-
tori ai matricei de covarianță, include funcții trigonometrice ale unghiurilor noului axele de coordonate cu vechile axe ale caracteristicilor originale.
5.6 În conformitate cu proprietățile valorilor proprii și ale vectorilor, urmele matricelor de covarianță ale caracteristicilor originale și ale componentelor principale sunt egale. Cu alte cuvinte
tr S= tr S y = tr L (5.16)
s 11 + s 22 + ... + s mm = l 1 + l 2 + ... + l m,
acestea. suma valorilor proprii ale matricei de covarianță este egală cu suma varianțelor tuturor caracteristicilor originale. Prin urmare, se poate vorbi de o anumită valoare totală a dispersiei caracteristicilor originale egală cu tr S, și sistemul de valori proprii luate în considerare.
Faptul că prima componentă principală are o varianță maximă egală cu l 1 înseamnă automat că descrie și ponderea maximă a variației totale a caracteristicilor originale tr S. În mod similar, a doua componentă principală are a doua cea mai mare varianță l 2, care corespunde celei de-a doua cea mai mare pondere luată în considerare din variația totală a caracteristicilor originale etc.
Pentru fiecare componentă principală, este posibil să se determine proporția din variabilitatea totală a caracteristicilor originale pe care le descrie
5.7 Evident, ideea variației totale a unui set de caracteristici inițiale X 1, X 2, X 3, ..., X m, măsurate prin valoarea tr S, are sens numai dacă toate aceste caracteristici sunt măsurate în aceleași unități. În caz contrar, va trebui să adăugați variațiile, semne diferite, dintre care unele vor fi exprimate în milimetri pătrați, altele în kilograme pătrate, altele în radiani pătrați sau grade etc. Această dificultate poate fi evitată cu ușurință dacă trecem de la valorile numite ale caracteristicilor X ij la valorile lor normalizate z ij = (X ij - M i)./ S i unde M i și S i sunt media aritmetică și abaterea standard a caracteristicii i-a. Caracteristicile z normalizate au medii zero, variații de unități și nu sunt asociate cu nicio unitate de măsură. Matricea de covarianță a caracteristicilor inițiale S se va transforma într-o matrice de corelaţie R.
Tot ceea ce s-a spus despre componentele principale găsite pentru matricea de covarianță rămâne adevărat pentru matrice R. Aici este exact la fel, pe baza vectorilor proprii ai matricei de corelație b 1 , b 2 , b 3 , ..., b m, treceți de la caracteristicile inițiale z i la componentele principale y 1, y 2, y 3, ..., y m
y 1 = b 1"z
y 2 = b 2"z
y 3 = b 3"z
y m = b m "z .
Această transformare poate fi scrisă și în formă compactă
y = B"z ,

Figura 5.2. Semnificația geometrică a componentelor principale pentru două caracteristici normalizate z 1 și z 2
Unde y- vector de valori ale componentelor principale, B- matrice care include vectori proprii, z- vector de caracteristici inițiale normalizate. Egalitatea se dovedește a fi corectă
B"RB= ... ... … , (5.18)
unde l 1, l 2, l 3, ..., l m sunt valorile proprii ale matricei de corelație.
Rezultatele obținute prin analiza matricei de corelație diferă de rezultate similare pentru matricea de covarianță. În primul rând, acum este posibil să luăm în considerare trăsăturile măsurate în diferite unități. În al doilea rând, vectorii proprii și numerele găsite pentru matrice RȘi S, sunt de asemenea diferite. În al treilea rând, componentele principale determinate din matricea de corelație și pe baza valorilor normalizate ale caracteristicilor z se dovedesc a fi centrate - adică. având valori medii zero.
Din păcate, după ce s-au determinat vectorii proprii și numerele pentru matricea de corelație, este imposibil să se treacă de la aceștia la vectori și numere similare ale matricei de covarianță. În practică, componentele principale bazate pe o matrice de corelație sunt de obicei utilizate deoarece sunt mai universale.
5.8 Să luăm în considerare semnificația geometrică a componentelor principale determinate din matricea de corelație. Cazul a două semne z 1 și z 2 este clar aici. Sistemul de coordonate asociat acestor caracteristici normalizate are un punct zero situat în centrul graficului (Fig. 5.2). Punctul central al elipsei de corelație,
inclusiv toate observațiile individuale, va coincide cu centrul sistemului de coordonate. Evident, axa primei componente principale, care are variația maximă, va coincide cu cea mai mare axă a elipsei de corelație, iar coordonata celei de-a doua componente principale va fi orientată de-a lungul celei de-a doua axe a acestei elipse.
Trecerea de la sistemul de coordonate asociat caracteristicilor originale z 1 și z 2 la noile axe ale componentelor principale este echivalentă cu rotirea primelor axe cu un anumit unghi j. Varianțele caracteristicilor normalizate sunt egale cu 1 și folosind formula (5.14) putem găsi valoarea unghiului de rotație j egală cu 45 o. Atunci matricea vectorilor proprii, care poate fi determinată prin funcțiile trigonometrice ale acestui unghi folosind formula (5.15), va fi egală cu
Cos j sin j 1 1 1
B" = = .
Sin j cos j (2) 1/2 -1 1
Valorile proprii pentru cazul bidimensional sunt, de asemenea, ușor de găsit. Condiția (5.12) se dovedește a fi de forma
care corespunde ecuaţiei
l 2 - 2l + 1 - r 2 = 0,
care are două rădăcini
l 1 = 1 + r (5,19)
Astfel, principalele componente ale matricei de corelație pentru două caracteristici normalizate pot fi găsite folosind formule foarte simple
Y 1 = (z 1 + z 2) (5,20)
Y 2 = (z 1 - z 2)
Mijloacele lor aritmetice sunt egale cu zero, iar abaterile lor standard au valorile
s y1 = (l 1) 1/2 = (1 + r) 1/2
s y2 = (l 2) 1/2 = (1 - r) 1/2
5.9 În conformitate cu proprietățile valorilor proprii și ale vectorilor, urmele matricei de corelație a caracteristicilor originale și ale matricei valorilor proprii sunt egale. Variația totală a m caracteristici normalizate este egală cu m. Cu alte cuvinte
tr R= m = tr L (5.21)
l 1 + l 2 + l 3 + ... + l m = m.
Atunci ponderea variației totale a caracteristicilor originale descrise de a i-a componentă principală este egală cu
De asemenea, puteți introduce conceptul de P cn - ponderea variației totale a caracteristicilor originale descrise de primele n componente principale,
n l 1 + l 2 + ... + l n
P cn = S P i = . (5,23)
Faptul că pentru valorile proprii se observă un ordin de forma l 1 > l 2 > > l 3 > ... > l m înseamnă că relații similare vor fi caracteristice fracțiilor descrise de principalele componente ale variației
P 1 > P 2 > P 3 > ... > P m . (5,24)
Proprietatea (5.24) presupune o formă specifică de dependență a fracției acumulate P сn de n (Fig. 5.3). În acest caz, primele trei componente principale descriu cea mai mare parte a variabilității trăsăturilor. Aceasta înseamnă că adesea primele câteva componente principale pot reprezenta împreună până la 80 - 90% din variația totală a trăsăturilor, în timp ce fiecare componentă principală ulterioară va crește această proporție foarte ușor. Apoi, pentru o analiză și interpretare ulterioară, doar aceste câteva componente principale pot fi utilizate cu încredere că descriu cele mai importante modele de variabilitate și corelație intragrup.

Figura 5.3. Dependenţa ponderii variaţiei totale a trăsăturilor P cn descrise de primele n componente principale de valoarea n. Numărul de caracteristici m = 9

Figura 5.4. Către determinarea designului criteriului de sortare a componentelor principale
semne. Datorită acestui fapt, numărul de noi variabile informative cu care trebuie lucrat poate fi redus de 2-3 ori. Astfel, componentele principale au una mai importantă și proprietate utilă- simplifică semnificativ descrierea variațiilor caracteristicilor inițiale și o fac mai compactă. O astfel de reducere a numărului de variabile este întotdeauna de dorit, dar este asociată cu unele distorsiuni în pozițiile relative ale punctelor corespunzătoare observațiilor individuale în spațiul primelor componente principale în comparație cu spațiul m-dimensional al caracteristicilor originale. Aceste distorsiuni apar din încercarea de a stoarce spațiul caracteristicilor în spațiul primelor componente principale. Cu toate acestea, în statistica matematică este dovedit că dintre toate metodele care pot reduce semnificativ numărul de variabile, trecerea la componentele principale duce la cea mai mică distorsiune a structurii observațiilor asociate cu această reducere.
5.10 O problemă importantă în analiza componentelor principale este problema determinării cantității acestora pentru o analiză ulterioară. Este evident că o creștere a numărului de componente principale crește ponderea acumulată a variabilității luate în considerare P cn și o apropie de 1. În același timp, compactitatea descrierii rezultate scade. Alegerea numărului de componente principale care asigură simultan atât completitudinea cât și compactitatea descrierii se poate baza pe diferite criterii utilizate în practică. Să le enumerăm pe cele mai comune.
Primul criteriu se bazează pe considerația că numărul de componente principale luate în considerare ar trebui să ofere suficientă caracter complet informativ al descrierii. Cu alte cuvinte, componentele principale luate în considerare ar trebui să descrie cea mai mare parte a variabilității totale a caracteristicilor originale: până la 75 - 90%. Alegerea unui nivel specific al cotei acumulate P cn rămâne subiectivă și depinde atât de opinia cercetătorului, cât și de problema care se rezolvă.
Un alt criteriu similar (criteriul lui Kaiser) permite să se includă în considerare componente principale cu valori proprii mai mari decât 1. Se bazează pe considerația că 1 este varianța unei caracteristici inițiale normalizate. Aceasta este
Ei bine, includerea în considerare în continuare a tuturor componentelor principale cu valori proprii mai mari decât 1 înseamnă că luăm în considerare numai acele variabile noi care au variații ale cel puțin unei caracteristici originale. Criteriul Kaiser este foarte comun și utilizarea lui este inclusă în multe pachete software de procesare a datelor statistice atunci când este necesar să se stabilească valoarea minimă a valorii proprii luate în considerare, iar valoarea implicită este adesea egală cu 1.
Criteriul de screening al lui Cattell este ceva mai bine justificat teoretic. Aplicarea sa se bazează pe luarea în considerare a unui grafic pe care valorile tuturor valorilor proprii sunt reprezentate în ordine descrescătoare (Fig. 5.4). Criteriul lui Cattell se bazează pe efectul că o secvență trasată de valori ale valorilor proprii rezultate, de obicei, produce o linie concavă. Primele câteva valori proprii prezintă o scădere neliniară a nivelului lor. Totuși, pornind de la o anumită valoare proprie, scăderea acestui nivel devine aproximativ liniară și destul de plată. Includerea componentelor principale în considerație se termină cu cea a cărei valoare proprie începe secțiunea rectilinie, plană a graficului. Astfel, în Figura 5.4, în conformitate cu criteriul lui Cattell, numai primele trei componente principale ar trebui incluse în considerare, deoarece a treia valoare proprie este situată chiar la începutul secțiunii plane rectilinie a graficului.
Criteriul Cattell se bazează pe următoarele. Dacă luăm în considerare date despre m caracteristici, obținute artificial dintr-un tabel de numere aleatoare distribuite normal, atunci pentru acestea corelațiile dintre caracteristici vor fi complet aleatorii și vor fi apropiate de 0. Dacă aici se găsesc componentele principale, va fi posibil. să detecteze o scădere treptată a valorii valorilor proprii ale acestora, care are un caracter rectiliniu. Cu alte cuvinte, o scădere liniară a valorilor proprii poate indica absența semnelor de conexiuni non-aleatoare în informațiile corespunzătoare despre corelație.
5.11 La interpretarea componentelor principale, cel mai des sunt folosiți vectorii proprii, prezentați sub forma așa-numitelor încărcări - coeficienți de corelație a caracteristicilor originale cu componentele principale. Vectori proprii b i, care satisface egalitatea (5.18), se obțin în formă normalizată, astfel încât b i "b i= 1. Aceasta înseamnă că suma pătratelor elementelor fiecărui vector propriu este 1. Vectorii proprii ale căror elemente sunt încărcări pot fi găsiți cu ușurință folosind formula
un i= (l i) 1/2 b i . (5.25)
Cu alte cuvinte, prin înmulțirea formei normalizate a vectorului propriu cu rădăcina pătrată a valorii sale proprii, se poate obține un set de încărcări ale caracteristicilor originale pe componenta principală corespunzătoare. Pentru vectorii de sarcină, următoarea egalitate este adevărată: a i "a i= l i, adică suma pătratelor sarcinilor pe i-a principal componenta este egală cu i-a valoare proprie. Programele de calculator produc de obicei vectori proprii sub formă de încărcări. Dacă este necesar să se obţină aceşti vectori în formă normalizată b i acest lucru se poate face folosind o formulă simplă b i = un i/ (l i) 1/2.
5.12 Proprietățile matematice ale valorilor proprii și ale vectorilor sunt astfel încât, conform Sect. A.25 Anexa A este matricea de corelație originală. R poate fi reprezentat sub formă R = BLB", care poate fi scris și ca
R= l 1 b 1 b 1 "+ l 2 b 2 b 2 "+ l 3 b 3 b 3 "+ ... + l m b m b m " . (5.26)
De remarcat că oricare dintre termenii l i b i b i", corespunzător celei de-a i-a componente principale, este matrice pătrată
L i b i1 2 l i b i1 b i2 l i b i1 b i3 … l i b i1 b im
eu b i b i"= l i b i1 b i2 l i b i2 2 l i b i2 b i3 ... l i b i2 b im . (5,27)
... ... ... ... ...
l i b i1 b im l i b i2 b im l i b i3 b im ... l i b im 2
Aici b ij este elementul i-lea vector propriu al j-lea caracteristică originală. Orice termen diagonal al unei astfel de matrice l i b ij 2 este o anumită fracțiune din variația j-lea atribut descris de i-a componentă principală. Apoi, varianța oricărui j-lea atribut poate fi reprezentată ca
1 = l 1 b 1j 2 + l 2 b 2j 2 + l 3 b 3j 2 + ... + l m b mj 2 , (5.28)
adică extinderea acestuia în contribuţii în funcţie de toate componentele principale.
În mod similar, orice termen off-diagonal l i b ij b ik al matricei (5.27) este o parte din coeficientul de corelație r jk al caracteristicilor j-a și k-a luate în considerare de componenta a i-a principală. Apoi putem scrie expansiunea acestui coeficient ca sumă
r jk = l 1 b 1j b 1k + l 2 b 2j b 2k + ... + l m b mj b mk , (5.29)
contribuțiile tuturor m componentelor principale la acesta.
Astfel, din formulele (5.28) și (5.29) se poate observa clar că fiecare componentă principală descrie o anumită parte a varianței fiecărei caracteristici originale și coeficientul de corelație al fiecărei combinații.
Ținând cont de faptul că elementele formei normalizate a vectorilor proprii b ij sunt legate de sarcinile a ij prin relație simplă (5.25), extinderea (5.26) se poate scrie și în termenii vectorilor proprii ai sarcinilor. R = AA", care poate fi reprezentat și ca
R = a 1 a 1" + a 2 a 2" + a 3 a 3" + ... + a m a m" , (5.30)
acestea. ca suma contribuţiilor fiecăreia dintre cele m componente principale. Fiecare dintre aceste contribuții a i a i" poate fi scris ca o matrice
A i1 2 a i1 a i2 a i1 a i3 ... a i1 a im
a i1 a i2 a i2 2 a i2 a i3 ... a i2 a im
a i a i"= a i1 a i3 a i2 a i3 a i3 2 ... a i3 a im , (5.31)
... ... ... ... ...
a i1 a im a i2 a im a i3 a im ... a im 2
pe diagonalele cărora sunt plasate a ij 2 - contribuții la varianța caracteristicii j-a inițiale și elemente în afara diagonalei a ij a ik - există contribuții similare la coeficientul de corelație r jk al j-a și k -a caracteristici.
Metoda componentelor principale
Metoda componentelor principale(Engleză) Analiza componentelor principale, PCA ) este una dintre principalele modalități de reducere a dimensionalității datelor, pierzând cea mai mică cantitate de informații. Inventat de K. Pearson Karl Pearson ) in. Este utilizat în multe domenii, cum ar fi recunoașterea modelelor, viziunea computerizată, compresia datelor etc. Calculul componentelor principale se reduce la calcularea vectorilor proprii și a valorilor proprii ale matricei de covarianță a datelor originale. Uneori se numește metoda componentei principale Transformarea Karhunen-Loeve(Engleză) Karhunen-Loeve) sau transformarea Hotelling (ing. Hotelling transform). Alte modalități de reducere a dimensionalității datelor sunt metoda componentelor independente, scalarea multidimensională, precum și numeroase generalizări neliniare: metoda curbelor și varietăților principale, metoda hărților elastice, căutarea celei mai bune proiecții (ing. Urmărirea proiecției), metodele „gâtului de sticlă” ale rețelei neuronale etc.
Expunerea formală a problemei
Problema analizei componentelor principale are cel puțin patru versiuni de bază:
- date aproximative prin varietăți liniare de dimensiune inferioară;
- găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care răspândirea datelor (adică abaterea standard de la valoarea medie) este maximă;
- găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care distanța pătratică medie dintre puncte este maximă;
- pentru o variabilă aleatoare multidimensională dată, construiți o transformare ortogonală a coordonatelor astfel încât, ca rezultat, corelațiile dintre coordonatele individuale să devină zero.
Primele trei versiuni operează cu seturi finite de date. Sunt echivalente și nu folosesc nicio ipoteză despre generarea statistică a datelor. A patra versiune operează cu variabile aleatorii. Mulțimi finite apar aici ca mostre dintr-o distribuție dată, iar soluția primelor trei probleme apare ca o aproximare a „adevărata” transformare Karhunen-Loeve. Acest lucru ridică o întrebare suplimentară și nu în întregime trivială cu privire la acuratețea acestei aproximări.
Aproximarea datelor prin varietăți liniare
Ilustrație pentru celebra lucrare a lui K. Pearson (1901): puncte date pe un plan, - distanța de la linia dreaptă. Căutăm o linie directă care să minimizeze suma
Metoda componentelor principale a început cu problema celei mai bune aproximări a unui set finit de puncte prin drepte și plane (K. Pearson, 1901). Este dat un set finit de vectori. Pentru fiecare dintre toate varietățile liniare -dimensionale din, găsiți astfel încât suma abaterilor pătrate de la este minimă:
,unde este distanța euclidiană de la un punct la o varietate liniară. Orice varietate liniară -dimensională poate fi definită ca un set de combinații liniare, unde parametrii se desfășoară de-a lungul liniei reale și este un set ortonormal de vectori
,unde norma euclidiană este produsul scalar euclidian sau sub formă de coordonate:
.Soluția problemei de aproximare pentru este dată de o mulțime de varietăți liniare imbricate , . Aceste varietăți liniare sunt definite de un set ortonormal de vectori (vectori componente principale) și un vector. Vectorul este căutat ca soluție la problema de minimizare pentru:
.Vectorii componentelor principale pot fi găsiți ca soluții la probleme similare de optimizare:
1) centralizați datele (scădeți media): . Acum; 2) găsiți prima componentă principală ca soluție a problemei; . Dacă soluția nu este unică, atunci alegeți una dintre ele. 3) Scădeți din date proiecția pe prima componentă principală: ; 4) găsiți a doua componentă principală ca soluție a problemei. Dacă soluția nu este unică, atunci alegeți una dintre ele. … 2k-1) Scăderea proiecției pe a-a componentă principală (reamintim că proiecțiile pe componentele principale anterioare au fost deja scăzute): ; 2k) găsiți a k-a componentă principală ca soluție a problemei: . Dacă soluția nu este unică, atunci alegeți una dintre ele. ...
La fiecare pas pregătitor, scădem proiecția pe componenta principală anterioară. Vectorii găsiți sunt ortonormalizați pur și simplu ca urmare a rezolvării problemei de optimizare descrise, totuși, pentru a preveni ca erorile de calcul să perturbe ortogonalitatea reciprocă a vectorilor componentelor principale, aceștia pot fi incluși în condițiile problemei de optimizare.
Neunicitatea în definiție, pe lângă arbitrariul banal în alegerea semnului (și rezolvă aceeași problemă), poate fi mai semnificativă și poate apărea, de exemplu, din condițiile simetriei datelor. Ultima componentă principală este un vector unitar ortogonal cu toate precedentele.
Găsirea proiecțiilor ortogonale cu cea mai mare împrăștiere

Prima componentă principală maximizează varianța eșantionului a proiecției datelor
Să ni se dea un set centrat de vectori de date (media aritmetică este zero). Sarcina este de a găsi o transformare ortogonală într-un nou sistem de coordonate pentru care următoarele condiții ar fi adevărate:
Teoria descompunerii valorii singulare a fost creată de J. J. Sylvester. James Joseph Sylvester ) în oraș și se menționează în toate ghiduri detaliate pe teoria matricei.
Un algoritm iterativ simplu de descompunere a valorii singulare
Procedura principală este de a căuta cea mai bună aproximare a unei matrice arbitrare printr-o matrice de forma (unde - - vector dimensional și - - vector dimensional) folosind metoda celor mai mici pătrate:
Soluția acestei probleme este dată de iterații succesive folosind formule explicite. Pentru un vector fix, valorile care oferă un minim formei sunt determinate în mod unic și explicit din egalități:
În mod similar, cu un vector fix, se determină valorile:
Ca o aproximare inițială a vectorului, luăm un vector aleatoriu de unitate de lungime, calculăm vectorul, apoi pentru acest vector calculăm vectorul etc. Fiecare pas reduce valoarea. Criteriul de oprire este micșorarea scăderii relative a valorii pasului de iterație funcțional minimizat () sau micimea valorii în sine.
Ca rezultat, am obținut cea mai bună aproximare pentru matrice folosind o matrice de formă (aici superscriptul indică numărul de aproximare). În continuare, scădem matricea rezultată din matrice, iar pentru matricea de deviație rezultată căutăm din nou cea mai bună aproximare de același tip etc., până când, de exemplu, norma devine suficient de mică. Ca rezultat, am obținut o procedură iterativă de descompunere a unei matrice sub forma unei sume de matrice de rang 1, adică . Presupunem și normalizăm vectorii: Ca rezultat, se obține o aproximare a numerelor singulare și a vectorilor singulari (dreapta - și stânga -).
Avantajele acestui algoritm includ simplitatea sa excepțională și capacitatea de a-l transfera aproape fără modificări ale datelor cu spații, precum și date ponderate.
Există diverse modificări ale algoritmului de bază care îmbunătățesc precizia și robustețea. De exemplu, vectorii componentelor principale pentru diferite ar trebui să fie ortogonali „prin construcție”, totuși, pentru un numar mare se acumulează iterații (dimensiune mare, multe componente), mici abateri de la ortogonalitate și poate fi necesară o corecție specială la fiecare pas pentru a-i asigura ortogonalitatea față de componentele principale găsite anterior.
Descompunerea singulară a tensorilor și metoda tensorilor componente principale
Adesea, vectorul de date are structura suplimentară a unui tabel dreptunghiular (de exemplu, o imagine plată) sau chiar a unui tabel multidimensional - adică un tensor: , . În acest caz, este, de asemenea, eficient să folosiți descompunerea valorii singulare. Definiția, formulele de bază și algoritmii sunt transferate practic fără modificări: în loc de o matrice de date, avem o valoare de index, unde primul indice este numărul punctului de date (tensor).
Procedura principală este de a căuta cea mai bună aproximare a unui tensor printr-un tensor de formă (unde este un vector -dimensional (este numărul de puncte de date), este un vector de dimensiune la ) folosind metoda celor mai mici pătrate:
Soluția acestei probleme este dată de iterații succesive folosind formule explicite. Dacă toți vectorii factori sunt dați cu excepția unuia, atunci acesta rămas este determinat în mod explicit din condiții suficiente pentru minim.
Ca o aproximare inițială a vectorilor (), luăm vectori aleatori de lungime unitară, calculăm vectorul, apoi pentru acest vector și acești vectori calculăm vectorul etc. (iterând ciclic prin indici) Fiecare pas reduce valoarea lui . Algoritmul converge evident. Criteriul de oprire este micșorarea scăderii relative a valorii funcționalei minimizate pe ciclu sau micimea valorii în sine. Apoi, scădem aproximarea rezultată din tensor și căutăm din nou cea mai bună aproximare de același tip pentru restul etc., până când, de exemplu, norma următorului rest devine suficient de mică.
Această descompunere a valorii singulare cu mai multe componente (metoda componentei principale a tensorilor) este utilizată cu succes în procesarea imaginilor, a semnalelor video și, mai larg, a oricăror date care au o structură tabelară sau tensorală.
Matrice de transformare în componente principale
Matricea de transformare a datelor în componente principale constă din vectori de componente principale, aranjați în ordinea descrescătoare a valorilor proprii:
(înseamnă transpunere),Adică, matricea este ortogonală.
Cea mai mare parte a variației datelor va fi concentrată în primele coordonate, ceea ce vă permite să vă mutați într-un spațiu de dimensiuni inferioare.
Varianta reziduala
Lasă datele să fie centrate, . Când se înlocuiesc vectorii de date cu proiecția lor pe primele componente principale, eroarea medie pătrată este introdusă pentru un vector de date:
unde sunt valorile proprii ale matricei de covarianță empirică, dispuse în ordine descrescătoare, ținând cont de multiplicitate.
Această cantitate se numește varianta reziduala. Magnitudinea
numit varianță explicată. Suma lor este egală cu varianța eșantionului. Eroarea relativă pătrată corespunzătoare este raportul dintre variația reziduală și varianța eșantionului (adică proporție de varianță inexplicabilă):
Eroarea relativă evaluează aplicabilitatea metodei componentelor principale cu proiecție pe primele componente.
cometariu: În majoritatea algoritmilor de calcul, valorile proprii cu vectorii proprii corespunzători - componentele principale - sunt calculate în ordine de la cel mai mare la cel mai mic. Pentru a-l calcula, este suficient să calculați primele valori proprii și urma matricei de covarianță empirică (suma elementelor diagonale, adică variațiile de-a lungul axelor). Apoi
Selectarea componentelor principale conform regulii lui Kaiser
Abordarea țintă pentru estimarea numărului de componente principale pe baza proporției necesare a varianței explicate este întotdeauna aplicabilă formal, dar presupune implicit că nu există nicio separare în „semnal” și „zgomot”, și orice precizie predeterminată are sens. Prin urmare, o altă euristică este adesea mai productivă, bazată pe ipoteza prezenței unui „semnal” (dimensiune relativ mică, amplitudine relativ mare) și „zgomot” (dimensiune mare, amplitudine relativ mică). Din acest punct de vedere, metoda componentelor principale funcționează ca un filtru: semnalul este conținut în principal în proiecția pe primele componente principale, iar proporția de zgomot în componentele rămase este mult mai mare.
Întrebare: cum se estimează numărul de componente principale necesare dacă raportul semnal-zgomot este necunoscut în prealabil?
Cea mai simplă și mai veche metodă de selectare a componentelor principale oferă regula Kaiser(Engleză) regula lui Kaiser): acele componente principale sunt semnificative pentru care
adică depășește media (varianța medie a eșantionului a coordonatelor vectorului de date). Regula lui Kaiser funcționează bine în cazurile simple în care există mai multe componente principale cu , mult mai mari decât media, iar valorile proprii rămase sunt mai mici decât aceasta. În cazuri mai complexe, poate produce prea multe componente principale semnificative. Dacă datele sunt normalizate la variația eșantionului unitar de-a lungul axelor, atunci regula lui Kaiser ia o formă deosebit de simplă: numai acele componente principale pentru care
Estimarea numărului de componente principale folosind regula bastonului rupt

Exemplu: estimarea numărului de componente principale folosind regula bastonului rupt în dimensiunea 5.
Una dintre cele mai populare abordări euristice pentru estimarea numărului de componente principale necesare este regula bastonului rupt(Engleză) Model stick rupt). Setul de valori proprii normalizate la suma unitară (, ) este comparat cu distribuția lungimii fragmentelor unui baston de lungime unitară ruptă la al treilea punct selectat aleatoriu (punctele de rupere sunt alese independent și sunt distribuite egal pe lungimea lui). bastonul). Fie () lungimile bucăților de trestie rezultate, numerotate în ordinea descrescătoare a lungimii: . Nu este greu de găsit așteptările matematice:
După regula bastonului rupt, vectorul propriu (în ordinea descrescătoare a valorilor proprii) este stocat în lista componentelor principale dacă
În fig. Un exemplu este dat pentru cazul cu 5 dimensiuni:
=(1+1/2+1/3+1/4+1/5)/5; =(1/2+1/3+1/4+1/5)/5; =(1/3+1/4+1/5)/5; =(1/4+1/5)/5; =(1/5)/5.De exemplu, selectat
=0.5; =0.3; =0.1; =0.06; =0.04.Conform regulii bastonului rupt, în acest exemplu ar trebui să lăsați 2 componente principale:
Conform evaluărilor utilizatorilor, regula bastonului rupt tinde să subestimeze numărul de componente principale semnificative.
Normalizare
Normalizare după reducerea la componentele principale
După proiecția pe primele componente principale cu este convenabil să se normalizeze la varianța unitară (eșantionului) de-a lungul axelor. Dispersia de-a lungul celei de-a doua componente principale este egală cu ), prin urmare, pentru a se normaliza, coordonatele corespunzătoare trebuie împărțite la . Această transformare nu este ortogonală și nu păstrează produsul punctual. Matricea de covarianță a proiecției datelor după normalizare devine unitate, proiecțiile către oricare două direcții ortogonale devin mărimi independente și orice bază ortonormală devine baza componentelor principale (amintim că normalizarea modifică relația de ortogonalitate a vectorilor). Maparea de la spațiul de date sursă la primele componente principale, împreună cu normalizarea, este specificată de matrice
.Această transformare este cea mai adesea numită transformarea Karhunen-Loeve. Aici sunt vectori coloană, iar superscriptul înseamnă transpunere.
Normalizare înainte de calcularea componentelor principale
Avertizare: nu trebuie confundată normalizarea efectuată după transformarea în componentele principale cu normalizarea și „nedimensionalizarea” atunci când preprocesarea datelor, efectuat înainte de calcularea componentelor principale. Este necesară o normalizare preliminară pentru a face o alegere rezonabilă a metricii în care se va calcula cea mai bună aproximare a datelor sau se vor căuta direcțiile celei mai mari împrăștiere (care este echivalentă). De exemplu, dacă datele sunt vectori tridimensionali de „metri, litri și kilograme”, atunci folosind distanța euclidiană standard, o diferență de 1 metru în prima coordonată va contribui la fel ca o diferență de 1 litru în a doua, sau 1 kg în al treilea . De obicei, sistemele de unități în care sunt prezentate datele originale nu reflectă cu acuratețe ideile noastre despre scările naturale de-a lungul axelor și se realizează „fără dimensiuni”: fiecare coordonată este împărțită într-o anumită scară determinată de date, de scopuri. a prelucrării acestora și a proceselor de măsurare și colectare a datelor.
Există trei abordări standard semnificativ diferite pentru o astfel de normalizare: varianța unitară de-a lungul axelor (scalele de-a lungul axelor sunt egale cu abaterile pătratice medii - după această transformare, matricea de covarianță coincide cu matricea coeficienților de corelație), pe precizie egală de măsurare(scara de-a lungul axei este proporțională cu precizia măsurării unei valori date) și pe cereri egaleîn problemă (scara de-a lungul axei este determinată de precizia necesară a prognozei unei anumite valori sau de distorsiunea permisă a acesteia - nivelul de toleranță). Alegerea preprocesării este influențată de formularea semnificativă a problemei, precum și de condițiile de colectare a datelor (de exemplu, dacă colectarea datelor este fundamental incompletă și datele vor fi încă primite, atunci este irațional să alegeți normalizarea strict la unitate. varianță, chiar dacă aceasta corespunde sensului problemei, deoarece aceasta implică renormalizarea tuturor datelor după primirea unei noi porțiuni; este mai rezonabil să alegeți o scară care să estimeze aproximativ deviație standard, și nu-l mai schimbați).
Pre-normalizarea la variația unității de-a lungul axelor este distrusă prin rotația sistemului de coordonate dacă axele nu sunt componente principale, iar normalizarea în timpul preprocesării datelor nu înlocuiește normalizarea după normalizarea la componentele principale.
Analogie mecanică și analiza componentelor principale pentru datele ponderate
Dacă atribuim o unitate de masă fiecărui vector de date, atunci matricea de covarianță empirică coincide cu tensorul de inerție al acestui sistem de masă punctuală (împărțit la masa totală), iar problema componentelor principale coincide cu problema reducerii tensorului de inerție la axele principale. Puteți folosi o libertate suplimentară în alegerea valorilor de masă pentru a ține cont de importanța punctelor de date sau de fiabilitatea valorilor acestora (datele importante sau datele din surse mai sigure li se atribuie mase mai mari). Dacă vectorului de date i se da masa, atunci în loc de matricea de covarianță empirică obținem
Toate operațiunile ulterioare de reducere la componentele principale sunt efectuate în același mod ca în versiunea principală a metodei: căutăm o bază proprie ortonormală, o ordonăm în ordinea descrescătoare a valorilor proprii, estimăm eroarea medie ponderată a aproximării datelor prin primele componente (pe baza sumelor valorilor proprii), normalizare etc.
O metodă mai generală de cântărire dă maximizarea sumei ponderate a distanțelor pe perechiîntre proiecţii. Pentru fiecare două puncte de date, se introduce o pondere; Și . În loc de matricea de covarianță empirică, folosim
Când matricea simetrică este pozitivă definită, deoarece forma pătratică este pozitivă:
În continuare, căutăm o bază proprie ortonormală, o aranjam în ordinea descrescătoare a valorilor proprii, estimăm eroarea medie ponderată a aproximării datelor de către primele componente etc. - exact la fel ca în algoritmul principal.
Se folosește această metodă dacă există cursuri: pentru clase diferite ponderea este aleasă să fie mai mare decât pentru punctele din aceeași clasă. Ca urmare, în proiecția pe componentele principale ponderate, diferitele clase sunt „depărtate” cu o distanță mai mare.
Alte utilizări - reducerea impactului abaterilor mari(alocați, engleză) Outlier ), care poate distorsiona imaginea datorită utilizării distanței pătrate medii: dacă alegeți , influența abaterilor mari va fi redusă. Astfel, modificarea descrisă a metodei componentelor principale este mai robustă decât cea clasică.
Terminologie specială
În statistică, atunci când se utilizează metoda componentelor principale, se folosesc mai mulți termeni speciali.
Data Matrix; fiecare linie este un vector preprocesate date ( centrat si drept standardizate), numărul de rânduri - (numărul de vectori de date), numărul de coloane - (dimensiunea spațiului de date);
Matricea de încărcare(Încărcări) ; fiecare coloană este un vector de componente principale, numărul de rânduri este (dimensiunea spațiului de date), numărul de coloane este (numărul de vectori ale componentelor principale selectate pentru proiecție);
Matricea contului(Scoruri); fiecare linie este o proiecție a vectorului de date pe componentele principale; număr de rânduri - (număr de vectori de date), număr de coloane - (număr de vectori componente principale selectate pentru proiecție);
Matricea scorului Z(scoruri Z); fiecare linie este o proiecție a vectorului de date pe componentele principale, normalizată la varianța eșantionului unitar; număr de rânduri - (număr de vectori de date), număr de coloane - (număr de vectori componente principale selectate pentru proiecție);
Matricea erorilor(sau resturi) (Erori sau reziduuri) .
Formula de baza:
Limite de aplicabilitate și limitări ale eficacității metodei
Metoda componentei principale este întotdeauna aplicabilă. Afirmația comună că se aplică numai datelor distribuite în mod normal (sau pentru distribuții apropiate de normal) este incorectă: în formularea originală a lui K. Pearson problema este stabilită: aproximări set finit de date și nu există nici măcar o ipoteză despre generarea lor statistică, ca să nu mai vorbim despre distribuția lor.
Cu toate acestea, metoda nu este întotdeauna eficientă în reducerea dimensionalității, având în vedere constrângerile de precizie. Liniile drepte și planele nu oferă întotdeauna o bună aproximare. De exemplu, datele pot urma o curbă cu o precizie bună, dar această curbă poate fi dificil de localizat în spațiul de date. În acest caz, metoda componentelor principale pentru o acuratețe acceptabilă va necesita mai multe componente (în loc de una) sau nu va reduce deloc dimensionalitatea cu o acuratețe acceptabilă. Pentru a face față unor astfel de componente principale „curbate”, au fost inventate metoda distribuției principale și diferite versiuni ale metodei componentelor principale neliniare. Datele de topologie complexe pot cauza mai multe probleme. De asemenea, au fost inventate diverse metode pentru a le aproxima, cum ar fi hărți Kohonen auto-organizate, gaz neural sau gramaticile topologice. Dacă datele sunt generate statistic cu o distribuție care este foarte diferită de cea normală, atunci pentru a aproxima distribuția este util să treceți de la componentele principale la componente independente, care nu mai sunt ortogonale în produsul scalar original. În cele din urmă, pentru o distribuție izotropă (chiar și una normală), în loc de un elipsoid de împrăștiere obținem o minge și este imposibil să reducem dimensiunea prin metode de aproximare.
Exemple de utilizare
Vizualizarea datelor
Vizualizarea datelor este o reprezentare vizuală a datelor experimentale sau a rezultatelor cercetării teoretice.
Prima alegere în vizualizarea unui set de date este de a proiecta ortogonal pe un plan primele două componente principale (sau spațiul tridimensional al primei trei principale componentă). Planul de proiectare este în esență un „ecran” plat bidimensional poziționat astfel încât să ofere o „imagine” a datelor cu cea mai mică distorsiune. O astfel de proiecție va fi optimă (dintre toate proiecțiile ortogonale pe diferite ecrane bidimensionale) din trei aspecte:
- Suma pătratelor distanțelor de la punctele de date la proiecțiile pe planul primelor componente principale este minimă, adică ecranul este situat cât mai aproape de norul de puncte.
- Suma distorsiunilor pătratului distanțelor dintre toate perechile de puncte din norul de date după proiectarea punctelor în plan este minimă.
- Suma distorsiunilor pătratului distanțelor dintre toate punctele de date și „centrul lor de greutate” este minimă.
Vizualizarea datelor este una dintre cele mai utilizate aplicații ale analizei componentelor principale și ale generalizărilor sale neliniare.
Compresie imagini și video
Pentru a reduce redundanța spațială a pixelilor la codificarea imaginilor și videoclipurilor, sunt utilizate transformări liniare ale blocurilor de pixeli. Cuantificarea ulterioară a coeficienților obținuți și codarea fără pierderi permite obținerea unor rapoarte de compresie semnificative. Utilizarea transformării PCA ca transformare liniară este, pentru unele tipuri de date, optimă în ceea ce privește dimensiunea datelor rezultate, menținând în același timp aceeași distorsiune. În prezent, această metodă nu este utilizată în mod activ, în principal datorită complexității sale de calcul ridicate. Comprimarea datelor poate fi realizată și prin eliminarea ultimilor coeficienți de conversie.
Reduceți zgomotul din imagini
Chimiometrie
Metoda componentei principale este una dintre metodele principale din chimiometrie. Chimiometrie ). Vă permite să împărțiți matricea de date sursă X în două părți: „cu sens” și „zgomot”. Conform celei mai populare definiții, „Chimiometria este o disciplină chimică care aplică metode matematice, statistice și alte metode bazate pe logica formală pentru a construi sau selecta metode optime de măsurare și proiecte experimentale, precum și pentru a extrage cele mai importante informații în analiza experimentală. date."
Psihodiagnostic
- analiza datelor (descrierea rezultatelor sondajelor sau a altor studii prezentate sub formă de matrice de date numerice);
- descrierea fenomenelor sociale (construcția de modele de fenomene, inclusiv modele matematice).
În științe politice, metoda componentei principale a fost instrumentul principal al proiectului „Atlasul politic al modernității” pentru analiza liniară și neliniară a evaluărilor a 192 de țări ale lumii în funcție de cinci indici integrali special dezvoltați (standard de trai, influență internațională, amenințări). , statalitate și democrație). Pentru a mapa rezultatele acestei analize, a fost dezvoltat un GIS (Geographic Information System) special, care combină spațiul geografic cu spațiul caracteristic. Hărțile de date ale atlasului politic au fost create, de asemenea, folosind ca bază varietăți principale bidimensionale în spațiul cincidimensional al țărilor. Diferența dintre o hartă de date și o hartă geografică este aceea harta geograficaîn apropiere apar obiecte care au coordonate geografice similare, în timp ce pe harta de date sunt în apropiere obiecte (țări) cu caracteristici (indici) similare.