Confidence intervals.
Calculation confidence interval is based on the average error of the corresponding parameter. Confidence interval shows within what limits with probability (1-a) the true value of the estimated parameter lies. Here a is the significance level, (1-a) is also called confidence probability.
In the first chapter we showed that, for example, for the arithmetic mean, the true population mean in approximately 95% of cases lies within 2 standard errors of the mean. Thus, the boundaries of the 95% confidence interval for the mean will be separated from the sample mean by twice the mean error of the mean, i.e. we multiply the average error of the mean by a certain coefficient depending on the confidence level. For the average and difference of averages, the Student coefficient is taken (the critical value of the Student's test), for the share and difference of shares, the critical value of the z criterion. The product of the coefficient and the average error can be called the maximum error of a given parameter, i.e. the maximum that we can obtain when assessing it.
Confidence interval for arithmetic mean : .
Here is the sample mean;
Average error of the arithmetic mean;
s – sample standard deviation;
n
f = n-1 (Student's coefficient).
Confidence interval for differences of arithmetic means :
Here is the difference between sample means;
 - average error of the difference between arithmetic means;
- average error of the difference between arithmetic means;
s 1 , s 2 – sample standard deviations;
n1,n2
The critical value of the Student's test for a given significance level a and the number of degrees of freedom f=n 1 +n 2-2 (Student's coefficient).
Confidence interval for shares :
![]() .
.
Here d is the sample fraction;
– average fraction error;
n– sample size (group size);
Confidence interval for difference of shares :
Here is the difference in sample shares;
 – average error of the difference between arithmetic means;
– average error of the difference between arithmetic means;
n1,n2– sample volumes (number of groups);
The critical value of the z criterion at a given significance level a ( , , ).
By calculating confidence intervals for the difference between indicators, we, firstly, directly see the possible values of the effect, and not just its point estimate. Secondly, we can draw a conclusion about the acceptance or rejection of the null hypothesis and, thirdly, we can draw a conclusion about the power of the test.
When testing hypotheses using confidence intervals, one must adhere to next rule:
If the 100(1-a) percent confidence interval of the difference in means does not contain zero, then the differences are statistically significant at significance level a; on the contrary, if this interval contains zero, then the differences are not statistically significant.
Indeed, if this interval contains zero, it means that the indicator being compared may be either greater or less in one of the groups compared to the other, i.e. the observed differences are due to chance.
The power of the test can be judged by the location of zero within the confidence interval. If zero is close to the lower or upper limit of the interval, then it is possible that with a larger number of groups being compared, the differences would reach statistical significance. If zero is close to the middle of the interval, then it means that both an increase and a decrease in the indicator in the experimental group are equally likely, and, probably, there really are no differences.
Examples:
To compare surgical mortality when using two different types of anesthesia: 61 people were operated on with the first type of anesthesia, 8 died, with the second type – 67 people, 10 died.
d 1 = 8/61 = 0.131; d2 = 10/67 = 0.149; d1-d2 = - 0.018.
The difference in lethality of the compared methods will be in the range (-0.018 - 0.122; -0.018 + 0.122) or (-0.14; 0.104) with a probability of 100(1-a) = 95%. The interval contains zero, i.e. hypothesis about the same lethality in two different types Anesthesia cannot be rejected.
Thus, the mortality rate can and will decrease to 14% and increase to 10.4% with a probability of 95%, i.e. zero is approximately in the middle of the interval, so it can be argued that, most likely, these two methods really do not differ in lethality.
In the example discussed earlier, the average pressing time during the tapping test was compared in four groups of students who differed in exam scores. Let's calculate the confidence intervals for the average pressing time for students who passed the exam with grades 2 and 5 and the confidence interval for the difference between these averages.
Student's coefficients are found using Student's distribution tables (see appendix): for the first group: = t(0.05;48) = 2.011; for the second group: = t(0.05;61) = 2.000. Thus, confidence intervals for the first group: = (162.19-2.011*2.18; 162.19+2.011*2.18) = (157.8; 166.6), for the second group (156.55- 2,000*1.88; 156.55+2,000*1.88) = (152.8; 160.3). So, for those who passed the exam with 2, the average pressing time ranges from 157.8 ms to 166.6 ms with a probability of 95%, for those who passed the exam with 5 – from 152.8 ms to 160.3 ms with a probability of 95%.
You can also test the null hypothesis using confidence intervals for means, and not just for the difference in means. For example, as in our case, if the confidence intervals for the means overlap, then the null hypothesis cannot be rejected. To reject a hypothesis at a chosen significance level, the corresponding confidence intervals must not overlap.
Let's find the confidence interval for the difference in the average pressing time in the groups that passed the exam with grades 2 and 5. Difference of averages: 162.19 – 156.55 = 5.64. Student's coefficient: = t(0.05;49+62-2) = t(0.05;109) = 1.982. Group standard deviations will be equal to: ; . We calculate the average error of the difference between the means: . Confidence interval: =(5.64-1.982*2.87; 5.64+1.982*2.87) = (-0.044; 11.33).
So, the difference in the average pressing time in the groups that passed the exam with 2 and 5 will be in the range from -0.044 ms to 11.33 ms. This interval includes zero, i.e. The average pressing time for those who passed the exam well may either increase or decrease compared to those who passed the exam unsatisfactorily, i.e. the null hypothesis cannot be rejected. But zero is very close to the lower limit, and the pressing time is much more likely to decrease for those who passed well. Thus, we can conclude that there are still differences in the average time of pressing between those who passed 2 and 5, we just could not detect them given the change in the average time, the spread of the average time and the sample sizes.
The power of a test is the probability of rejecting an incorrect null hypothesis, i.e. find differences where they actually exist.
The power of the test is determined based on the level of significance, the magnitude of differences between groups, the spread of values in groups and the size of samples.
For Student's t test and analysis of variance, sensitivity diagrams can be used.
The power of the criterion can be used to preliminarily determine the required number of groups.
The confidence interval shows within which limits the true value of the estimated parameter lies with a given probability.
Using confidence intervals, you can test statistical hypotheses and draw conclusions about the sensitivity of criteria.
LITERATURE.
Glanz S. – Chapter 6,7.
Rebrova O.Yu. – p.112-114, p.171-173, p.234-238.
Sidorenko E.V. – p.32-33.
Questions for self-testing of students.
1. What is the power of the criterion?
2. In what cases is it necessary to evaluate the power of criteria?
3. Methods for calculating power.
6. How to test a statistical hypothesis using a confidence interval?
7. What can be said about the power of the criterion when calculating the confidence interval?
Tasks.
In the previous subsections we considered the issue of estimating an unknown parameter A one number. This is called a “point” estimate. In a number of tasks, you not only need to find for the parameter A suitable numerical value, but also to evaluate its accuracy and reliability. You need to know what errors replacing a parameter can lead to A its point estimate A and with what degree of confidence can we expect that these errors will not exceed known limits?
Problems of this kind are especially relevant with a small number of observations, when the point estimate and in is largely random and approximate replacement of a by a can lead to serious errors.
To give an idea of the accuracy and reliability of the estimate A,
V mathematical statistics They use so-called confidence intervals and confidence probabilities.
Let for the parameter A unbiased estimate obtained from experience A. We want to estimate the possible error in this case. Let us assign some sufficiently large probability p (for example, p = 0.9, 0.95 or 0.99) such that an event with probability p can be considered practically reliable, and find a value s for which
Then the range is practically possible values error that occurs when replacing A on A, will be ± s; big by absolute value errors will appear only with a low probability a = 1 - p. Let's rewrite (14.3.1) as:
Equality (14.3.2) means that with probability p the unknown value of the parameter A falls within the interval
It is necessary to note one circumstance. Previously, we have repeatedly considered the probability of a random variable falling into a given non-random interval. Here the situation is different: the magnitude A is not random, but the interval / p is random. Its position on the x-axis is random, determined by its center A; In general, the length of the interval 2s is also random, since the value of s is calculated, as a rule, from experimental data. Therefore, in this case, it would be better to interpret the p value not as the probability of “hitting” the point A in the interval / p, and as the probability that a random interval / p will cover the point A(Fig. 14.3.1).

Rice. 14.3.1
The probability p is usually called confidence probability, and interval / p - confidence interval. Interval boundaries If. a x =a- s and a 2 = a + and are called trust boundaries.
Let's give another interpretation to the concept of a confidence interval: it can be considered as an interval of parameter values A, compatible with experimental data and not contradicting them. Indeed, if we agree to consider an event with probability a = 1-p practically impossible, then those values of the parameter a for which a - a> s must be recognized as contradicting experimental data, and those for which |a - A a t na 2 .
Let for the parameter A there is an unbiased estimate A. If we knew the law of distribution of the quantity A, the task of finding a confidence interval would be very simple: it would be enough to find a value s for which
![]()
The difficulty is that the law of distribution of estimates A depends on the distribution law of the quantity X and, therefore, on its unknown parameters (in particular, on the parameter itself A).
To get around this difficulty, you can use the following roughly approximate technique: replace the unknown parameters in the expression for s with their point estimates. With a relatively large number of experiments P(about 20...30) this technique usually gives results that are satisfactory in terms of accuracy.
As an example, consider the problem of a confidence interval for the mathematical expectation.
Let it be produced P X, whose characteristics are the mathematical expectation T and variance D- unknown. The following estimates were obtained for these parameters:

It is required to construct a confidence interval / p corresponding to the confidence probability p for the mathematical expectation T quantities X.
When solving this problem, we will use the fact that the quantity T represents the sum P independent identically distributed random variables Xh and according to the central limit theorem, for a sufficiently large P its distribution law is close to normal. In practice, even with a relatively small number of terms (about 10...20), the distribution law of the sum can be approximately considered normal. We will assume that the value T distributed according to the normal law. The characteristics of this law - mathematical expectation and variance - are equal, respectively T And
(see chapter 13 subsection 13.3). Let us assume that the value D we know and will find a value Ep for which
Using formula (6.3.5) of Chapter 6, we express the probability on the left side of (14.3.5) through the normal distribution function
where is the standard deviation of the estimate T.
From Eq.

find the value of Sp: 
where arg Ф* (х) is the inverse function of Ф* (X), those. such a value of the argument for which the normal distribution function is equal to X.
Dispersion D, through which the quantity is expressed A 1P, we do not know exactly; as its approximate value, you can use the estimate D(14.3.4) and put approximately:

Thus, the problem of constructing a confidence interval has been approximately solved, which is equal to:
where gp is determined by formula (14.3.7).
To avoid reverse interpolation in the tables of the function Ф* (l) when calculating s p, it is convenient to compile a special table (Table 14.3.1), which gives the values of the quantity
depending on r. The value (p determines for the normal law the number of standard deviations that must be plotted to the right and left from the center of dispersion so that the probability of getting into the resulting area is equal to p.
Using the value 7 p, the confidence interval is expressed as:

Table 14.3.1
Example 1. 20 experiments were carried out on the quantity X; the results are shown in table. 14.3.2.
Table 14.3.2
It is required to find an estimate from for the mathematical expectation of the quantity X and construct a confidence interval corresponding to the confidence probability p = 0.8.
Solution. We have:

Choosing l: = 10 as the reference point, using the third formula (14.2.14) we find the unbiased estimate D :

According to the table 14.3.1 we find ![]()
![]()
Confidence limits:

Confidence interval:
![]()
Parameter values T, lying in this interval are compatible with the experimental data given in table. 14.3.2.
A confidence interval for the variance can be constructed in a similar way.
Let it be produced P independent experiments on random variable X with unknown parameters for both A and dispersion D an unbiased estimate was obtained:


It is required to approximately construct a confidence interval for the variance.
From formula (14.3.11) it is clear that the quantity D represents
amount P random variables of the form . These values are not
independent, since any of them includes the quantity T, dependent on everyone else. However, it can be shown that with increasing P the distribution law of their sum also approaches normal. Almost at P= 20...30 it can already be considered normal.
Let's assume that this is so, and let's find the characteristics of this law: mathematical expectation and dispersion. Since the assessment D- unbiased, then M[D] = D.
Variance calculation D D is associated with relatively complex calculations, so we present its expression without derivation:
where q 4 is the fourth central moment of the magnitude X.
To use this expression, you need to substitute the values \u003d 4 and D(at least close ones). Instead of D you can use his assessment D. In principle, the fourth central moment can also be replaced by an estimate, for example, a value of the form:

but such a replacement will give extremely low accuracy, since in general, with a limited number of experiments, high-order moments are determined with large errors. However, in practice it often happens that the type of quantity distribution law X known in advance: only its parameters are unknown. Then you can try to express μ 4 through D.
Let's take the most common case, when the value X distributed according to the normal law. Then its fourth central moment is expressed in terms of dispersion (see Chapter 6, subsection 6.2);
![]()
and formula (14.3.12) gives  or
or
Replacing the unknown in (14.3.14) D his assessment D, we get: from where 
Moment μ 4 can be expressed through D also in some other cases, when the distribution of the value X is not normal, but its appearance is known. For example, for the law of uniform density (see Chapter 5) we have: 
where (a, P) is the interval on which the law is specified.
Hence,
![]()
Using formula (14.3.12) we obtain:  where do we find approximately
where do we find approximately
In cases where the type of the distribution law for the quantity 26 is unknown, when making an approximate estimate of the value a/) it is still recommended to use formula (14.3.16), unless there are special reasons to believe that this law is very different from the normal one (has a noticeable positive or negative kurtosis) .
If the approximate value a/) is obtained in one way or another, then we can construct a confidence interval for the variance in the same way as we built it for the mathematical expectation:
where the value depending on the given probability p is found according to the table. 14.3.1.
Example 2. Find approximately 80% confidence interval for the variance of a random variable X under the conditions of example 1, if it is known that the value X distributed according to a law close to normal.
Solution. The value remains the same as in the table. 14.3.1:
![]()
According to the formula (14.3.16)

Using formula (14.3.18) we find the confidence interval:
![]()
The corresponding range of standard deviation values: (0.21; 0.29).
14.4. Exact methods for constructing confidence intervals for the parameters of a random variable distributed according to a normal law
In the previous subsection, we examined roughly approximate methods for constructing confidence intervals for mathematical expectation and variance. Here we will give an idea of the exact methods to solve the same problem. We emphasize that in order to accurately find confidence intervals it is absolutely necessary to know in advance the form of the distribution law of the quantity X, whereas for the application of approximate methods this is not necessary.
The idea of accurate methods for constructing confidence intervals comes down to the following. Any confidence interval is found from a condition expressing the probability of fulfilling certain inequalities, which include the estimate we are interested in A. Law of valuation distribution A V general case depends on unknown quantity parameters X. However, sometimes it is possible to pass in inequalities from a random variable A to some other function of observed values X p X 2, ..., X p. the distribution law of which does not depend on unknown parameters, but depends only on the number of experiments and on the type of the distribution law of the quantity X. These kinds of random variables play an important role in mathematical statistics; they have been studied in most detail for the case of a normal distribution of the quantity X.
For example, it has been proven that with a normal distribution of the value X random value

obeys the so-called Student distribution law With P- 1 degrees of freedom; the density of this law has the form

where G(x) is the known gamma function:

It has also been proven that the random variable
has a "%2 distribution" with P- 1 degrees of freedom (see Chapter 7), the density of which is expressed by the formula

Without dwelling on the derivations of distributions (14.4.2) and (14.4.4), we will show how they can be applied when constructing confidence intervals for parameters ty D.
Let it be produced P independent experiments on a random variable X, normally distributed with unknown parameters T&O. For these parameters, estimates were obtained

It is required to construct confidence intervals for both parameters corresponding to the confidence probability p.
Let's first construct a confidence interval for the mathematical expectation. It is natural to take this interval symmetrical with respect to T; let s p denote half the length of the interval. The value s p must be chosen so that the condition is satisfied
Let's try to move on the left side of equality (14.4.5) from the random variable T to a random variable T, distributed according to Student's law. To do this, multiply both sides of the inequality |m-w?|
by a positive value:  or, using notation (14.4.1),
or, using notation (14.4.1),

Let's find a number / p such that the value / p can be found from the condition

From formula (14.4.2) it is clear that (1) is an even function, therefore (14.4.8) gives 
Equality (14.4.9) determines the value / p depending on p. If you have at your disposal a table of integral values

then the value of /p can be found by reverse interpolation in the table. However, it is more convenient to draw up a table of /p values in advance. Such a table is given in the Appendix (Table 5). This table shows the values depending on the confidence level p and the number of degrees of freedom P- 1. Having determined / p from the table. 5 and assuming 
we will find half the width of the confidence interval / p and the interval itself
Example 1. 5 independent experiments were performed on a random variable X, normally distributed with unknown parameters T and about. The results of the experiments are given in table. 14.4.1.
Table 14.4.1
Find rating T for the mathematical expectation and construct a 90% confidence interval / p for it (i.e., the interval corresponding to the confidence probability p = 0.9).
Solution. We have:
![]()
According to table 5 of the application for P - 1 = 4 and p = 0.9 we find ![]() where
where 
The confidence interval will be
Example 2. For the conditions of example 1 of subsection 14.3, assuming the value X normally distributed, find the exact confidence interval.
Solution. According to table 5 of the appendix we find when P - 1 = 19ir =
0.8 / p = 1.328; from here 
Comparing with the solution of example 1 of subsection 14.3 (e p = 0.072), we are convinced that the discrepancy is very insignificant. If we maintain the accuracy to the second decimal place, then the confidence intervals found by the exact and approximate methods coincide:
![]()
Let's move on to constructing a confidence interval for the variance. Consider the unbiased variance estimator

and express the random variable D through magnitude V(14.4.3), having distribution x 2 (14.4.4):

Knowing the law of distribution of quantity V, you can find the interval /(1) in which it falls with a given probability p.
Law of distribution kn_x(v) magnitude I 7 has the form shown in Fig. 14.4.1.

Rice. 14.4.1
The question arises: how to choose the interval / p? If the law of distribution of magnitude V was symmetrical (like normal law or Student distribution), it would be natural to take the interval /p symmetric with respect to the mathematical expectation. In this case the law k p_x (v) asymmetrical. Let us agree to choose the interval /p so that the probability of the value being V beyond the interval to the right and left (shaded areas in Fig. 14.4.1) were the same and equal

To construct an interval /p with this property, we use the table. 4 applications: it contains numbers y) such that
![]()
for the value V, having x 2 -distribution with r degrees of freedom. In our case r = n- 1. Let's fix r = n- 1 and find in the corresponding row of the table. 4 two meanings x 2 - one corresponding to probability the other - probability Let us denote these
values at 2 And xl? The interval has y 2, with your left, and y~ right end.
Now let’s find from the interval / p the desired confidence interval /|, for the dispersion with boundaries D, and D2, which covers the point D with probability p: ![]()
Let us construct an interval / (, = (?> ь А) that covers the point D if and only if the value V falls into the interval /r. Let us show that the interval

satisfies this condition. Indeed, the inequalities  are equivalent to inequalities
are equivalent to inequalities
![]()
and these inequalities are satisfied with probability p. Thus, the confidence interval for the variance has been found and is expressed by formula (14.4.13).
Example 3. Find the confidence interval for the variance under the conditions of example 2 of subsection 14.3, if it is known that the value X normally distributed.
Solution. We have ![]() . According to table 4 of the appendix
. According to table 4 of the appendix
we find at r = n - 1 = 19

Using formula (14.4.13) we find the confidence interval for the variance ![]()
The corresponding interval for the standard deviation is (0.21; 0.32). This interval only slightly exceeds the interval (0.21; 0.29) obtained in example 2 of subsection 14.3 using the approximate method.
- Figure 14.3.1 considers a confidence interval symmetric about a. In general, as we will see later, this is not necessary.
From this article you will learn:
What's happened confidence interval?
What's the point 3 sigma rules?
How can you apply this knowledge in practice?
Nowadays, due to an overabundance of information associated with a large assortment of products, sales directions, employees, areas of activity, etc., it can be difficult to highlight the main thing, which, first of all, is worth paying attention to and making efforts to manage. Definition confidence interval and analysis of actual values going beyond its boundaries - a technique that will help you highlight situations, influencing changing trends. You will be able to develop positive factors and reduce the influence of negative ones. This technology is used in many well-known global companies.
There are so-called " alerts", which inform managers that the next value is in a certain direction went beyond confidence interval. What does this mean? This is a signal that some unusual event has occurred, which may change the existing trend in this direction. This is a signal to that to figure it out in the situation and understand what influenced it.
For example, consider several situations. We calculated the sales forecast with forecast limits for 100 product items for 2011 by month and actual sales in March:
- By " Sunflower oil» broke through the upper limit of the forecast and did not fall into the confidence interval.
- For “Dry yeast” we exceeded the lower limit of the forecast.
- By " Oatmeal"Breaked through the upper limit.
For other products, actual sales were within the given forecast limits. Those. their sales were within expectations. So, we identified 3 products that went beyond the borders and began to figure out what influenced them to go beyond the borders:
- With "Sunflower Oil" we entered a new trading network, which gave us additional sales volume, which led to us going beyond the upper limit. For this product, it is worth recalculating the forecast until the end of the year, taking into account the sales forecast for this network.
- For “Dry Yeast”, the car got stuck at customs, and there was a shortage within 5 days, which affected the decline in sales and exceeded the lower limit. It may be worthwhile to figure out what caused it and try not to repeat this situation.
- A sales promotion event was launched for Oatmeal Porridge, which gave a significant increase in sales and led to the company going beyond the forecast.
We identified 3 factors that influenced the going beyond the forecast limits. There can be much more of them in life. To increase the accuracy of forecasting and planning, factors that lead to the fact that actual sales may go beyond the forecast, it is worth highlighting and building forecasts and plans for them separately. And then consider their impact on the main sales forecast. You can also regularly assess the impact of these factors and change the situation for the better. by reducing the influence of negative and increasing the influence of positive factors.
With a confidence interval we can:
- Select directions, which are worth paying attention to, because events have occurred in these directions that may affect change in trend.
- Identify factors, which really influence the change in the situation.
- Accept informed decision(for example, about purchasing, planning, etc.).
Now let's look at what a confidence interval is and how to calculate it in Excel using an example.
What is a confidence interval?
Confidence interval is the forecast boundaries (upper and lower), within which with a given probability (sigma) actual values will appear.
Those. We calculate the forecast - this is our main guideline, but we understand that the actual values are unlikely to be 100% equal to our forecast. And the question arises, within what boundaries actual values may fall, if the current trend continues? And this question will help us answer confidence interval calculation, i.e. - upper and lower limits of the forecast.
What is a given probability sigma?
When calculating confidence interval we can set probability hits actual values within the given forecast limits. How to do it? To do this, we set the value of sigma and, if sigma is equal to:
3 sigma- then, the probability of the next actual value falling into the confidence interval will be 99.7%, or 300 to 1, or there is a 0.3% probability of going beyond the boundaries.
2 sigma- then, the probability of the next value falling within the boundaries is ≈ 95.5%, i.e. the odds are about 20 to 1, or there is a 4.5% chance of going overboard.
1 sigma- then the probability is ≈ 68.3%, i.e. the odds are approximately 2 to 1, or there is a 31.7% chance that the next value will fall outside the confidence interval.
We formulated 3 sigma rule,which says that hit probability another random value into the confidence interval with a given value three sigma is 99.7%.
The great Russian mathematician Chebyshev proved the theorem that there is a 10% probability of going beyond the forecast limits with a given value of three sigma. Those. the probability of falling within the 3-sigma confidence interval will be at least 90%, while an attempt to calculate the forecast and its boundaries “by eye” is fraught with much more significant errors.
How to calculate a confidence interval yourself in Excel?
Let's look at the calculation of the confidence interval in Excel (i.e., the upper and lower limits of the forecast) using an example. We have a time series - sales by month for 5 years. See attached file.
To calculate the forecast limits, we calculate:
- Sales forecast().
- Sigma - standard deviation forecast models from actual values.
- Three sigma.
- Confidence interval.
1. Sales forecast.
=(RC[-14] (time series data)- RC[-1] (model value))^2(squared)

3. For each month, let’s sum up the deviation values from stage 8 Sum((Xi-Ximod)^2), i.e. Let's sum up January, February... for each year.
To do this, use the formula =SUMIF()
SUMIF(array with period numbers inside the cycle (for months from 1 to 12); link to the period number in the cycle; link to an array with squares of the difference between the source data and period values)

4. Calculate the standard deviation for each period in the cycle from 1 to 12 (stage 10 in the attached file).
To do this, we extract the root from the value calculated at stage 9 and divide by the number of periods in this cycle minus 1 = SQRT((Sum(Xi-Ximod)^2/(n-1))
Let's use the formulas in Excel =ROOT(R8 (link to (Sum(Xi-Ximod)^2)/(COUNTIF($O$8:$O$67 (link to array with cycle numbers); O8 (link to a specific cycle number that we count in the array))-1))
Using the Excel formula = COUNTIF we count the number n

Having calculated the standard deviation of the actual data from the forecast model, we obtained the sigma value for each month - stage 10 in the attached file .
3. Let's calculate 3 sigma.
At stage 11 we set the number of sigmas - in our example “3” (stage 11 in the attached file):

Also convenient for practice sigma values:
1.64 sigma - 10% chance of exceeding the limit (1 chance in 10);
1.96 sigma - 5% chance of going beyond limits (1 chance in 20);
2.6 sigma - 1% chance of exceeding limits (1 chance in 100).
5) Calculating three sigma, for this we multiply the “sigma” values for each month by “3”.

3. Determine the confidence interval.
- Upper forecast limit- sales forecast taking into account growth and seasonality + (plus) 3 sigma;
- Lower forecast limit- sales forecast taking into account growth and seasonality – (minus) 3 sigma;
For the convenience of calculating the confidence interval for a long period (see attached file), we will use the Excel formula =Y8+VLOOKUP(W8,$U$8:$V$19,2,0), Where
Y8- sales forecast;
W8- the number of the month for which we will take the 3-sigma value;
Those. Upper forecast limit= “sales forecast” + “3 sigma” (in the example, VLOOKUP(month number; table with 3 sigma values; column from which we extract the sigma value equal to the month number in the corresponding row; 0)).

Lower forecast limit= “sales forecast” minus “3 sigma”.
So, we calculated the confidence interval in Excel.
Now we have a forecast and a range with boundaries within which the actual values will fall with a given sigma probability.
In this article we looked at what sigma is and rule of three sigma, how to determine the confidence interval and why you can use this technique in practice.
We wish you accurate forecasts and success!
How Forecast4AC PRO can help youwhen calculating the confidence interval?:
Forecast4AC PRO will automatically calculate the upper or lower bounds of the forecast for more than 1000 time series simultaneously;
The ability to analyze the boundaries of the forecast in comparison with the forecast, trend and actual sales on the chart with one keystroke;
In the Forcast4AC PRO program it is possible to set the sigma value from 1 to 3.
Join us!
Download free apps for forecasting and business analysis:

- Novo Forecast Lite- automatic forecast calculation V Excel.
- 4analytics - ABC-XYZ analysis and emissions analysis Excel.
- Qlik Sense Desktop and QlikViewPersonal Edition - BI systems for data analysis and visualization.
Test the capabilities of paid solutions:
- Novo Forecast PRO- forecasting in Excel for large data sets.
Target– teach students algorithms for calculating confidence intervals of statistical parameters.
When statistically processing data, the calculated arithmetic mean, coefficient of variation, correlation coefficient, difference criteria and other point statistics should receive quantitative confidence limits, which indicate possible fluctuations of the indicator in smaller and larger directions within the confidence interval.
Example 3.1
.
The distribution of calcium in the blood serum of monkeys, as previously established, is characterized by the following sample indicators: = 11.94 mg%;  = 0.127 mg%; n= 100. It is required to determine the confidence interval for the general average (
= 0.127 mg%; n= 100. It is required to determine the confidence interval for the general average (  ) with confidence probability P
= 0,95.
) with confidence probability P
= 0,95.
The general average is located with a certain probability in the interval:
 , Where
, Where  – sample arithmetic mean; t– Student’s test;
– sample arithmetic mean; t– Student’s test;  – error of the arithmetic mean.
– error of the arithmetic mean.
Using the table “Student’s t-test values” we find the value
 with a confidence probability of 0.95 and the number of degrees of freedom k= 100-1 = 99. It is equal to 1.982. Together with the values of the arithmetic mean and statistical error, we substitute it into the formula:
with a confidence probability of 0.95 and the number of degrees of freedom k= 100-1 = 99. It is equal to 1.982. Together with the values of the arithmetic mean and statistical error, we substitute it into the formula:
or 11.69  12,19
12,19
Thus, with a probability of 95%, it can be stated that the general average of this normal distribution is between 11.69 and 12.19 mg%.
Example 3.2
. Determine the boundaries of the 95% confidence interval for the general variance (  ) distribution of calcium in the blood of monkeys, if it is known that
) distribution of calcium in the blood of monkeys, if it is known that  = 1.60, at n
= 100.
= 1.60, at n
= 100.
To solve the problem you can use the following formula:
Where  – statistical error of dispersion.
– statistical error of dispersion.
We find the sampling variance error using the formula:  . It is equal to 0.11. Meaning t- criterion with a confidence probability of 0.95 and the number of degrees of freedom k= 100–1 = 99 is known from the previous example.
. It is equal to 0.11. Meaning t- criterion with a confidence probability of 0.95 and the number of degrees of freedom k= 100–1 = 99 is known from the previous example.
Let's use the formula and get:
or 1.38  1,82
1,82
More accurately, the confidence interval of the general variance can be constructed using  (chi-square) - Pearson test. The critical points for this criterion are given in a special table. When using the criterion
(chi-square) - Pearson test. The critical points for this criterion are given in a special table. When using the criterion  To construct a confidence interval, a two-sided significance level is used. For the lower limit, the significance level is calculated using the formula
To construct a confidence interval, a two-sided significance level is used. For the lower limit, the significance level is calculated using the formula  , for the top –
, for the top –  . For example, for the confidence level
. For example, for the confidence level  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. Accordingly, according to the table of distribution of critical values
= 0.990. Accordingly, according to the table of distribution of critical values  , with calculated confidence levels and number of degrees of freedom k= 100 – 1= 99, find the values
, with calculated confidence levels and number of degrees of freedom k= 100 – 1= 99, find the values  And
And  . We get
. We get  equals 135.80, and
equals 135.80, and 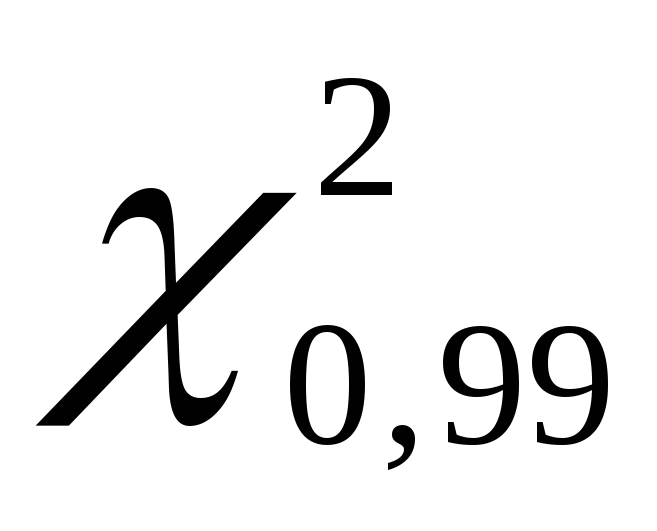 equals 70.06.
equals 70.06.
To find confidence limits for the general variance using  Let's use the formulas: for the lower boundary
Let's use the formulas: for the lower boundary  , for the upper bound
, for the upper bound  . Let's substitute the found values for the problem data
. Let's substitute the found values for the problem data  into formulas:
into formulas: 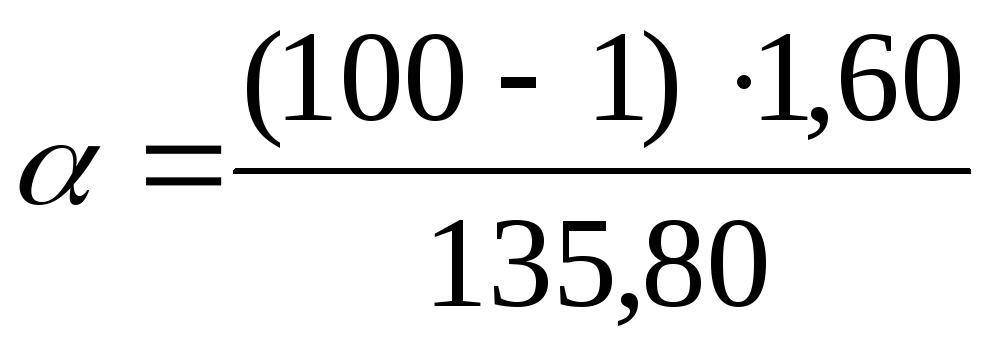 =
1,17;
=
1,17; = 2.26. Thus, with a confidence probability P= 0.99 or 99% general variance will lie in the range from 1.17 to 2.26 mg% inclusive.
= 2.26. Thus, with a confidence probability P= 0.99 or 99% general variance will lie in the range from 1.17 to 2.26 mg% inclusive.
Example 3.3 . Among 1000 wheat seeds from the batch received at the elevator, 120 seeds were found infected with ergot. It is necessary to determine the probable boundaries of the general proportion of infected seeds in a given batch of wheat.
It is advisable to determine the confidence limits for the general share for all its possible values using the formula:
 ,
,
Where n – number of observations; m– absolute size of one of the groups; t– normalized deviation.
The sample proportion of infected seeds is  or 12%. With confidence probability R= 95% normalized deviation ( t-Student's test at k
=
or 12%. With confidence probability R= 95% normalized deviation ( t-Student's test at k
=
 )t
= 1,960.
)t
= 1,960.
We substitute the available data into the formula:
Hence the boundaries of the confidence interval are equal to 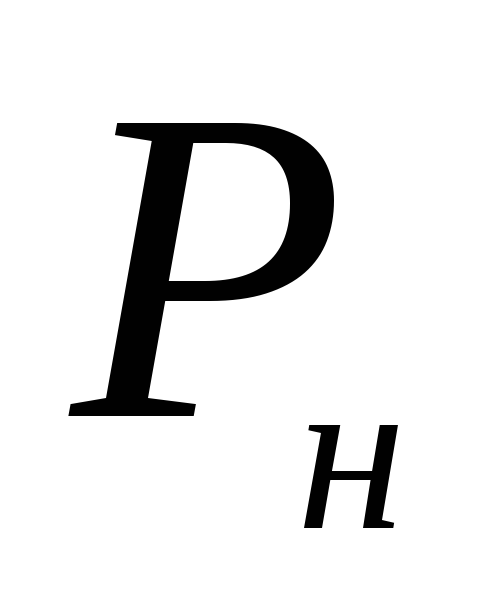 = 0.122–0.041 = 0.081, or 8.1%;
= 0.122–0.041 = 0.081, or 8.1%;  = 0.122 + 0.041 = 0.163, or 16.3%.
= 0.122 + 0.041 = 0.163, or 16.3%.
Thus, with a confidence probability of 95% it can be stated that the general proportion of infected seeds is between 8.1 and 16.3%.
Example 3.4 . The coefficient of variation characterizing the variation of calcium (mg%) in the blood serum of monkeys was equal to 10.6%. Sample size n= 100. It is necessary to determine the boundaries of the 95% confidence interval for the general parameter Cv.
Limits of the confidence interval for the general coefficient of variation Cv are determined by the following formulas:
 And
And  , Where K
intermediate value calculated by the formula
, Where K
intermediate value calculated by the formula  .
.
Knowing that with confidence probability R= 95% normalized deviation (Student's test at k
=
 )t
= 1.960, let’s first calculate the value TO:
)t
= 1.960, let’s first calculate the value TO:
 .
.
 or 9.3%
or 9.3%
 or 12.3%
or 12.3%
Thus, the general coefficient of variation with a 95% confidence level lies in the range from 9.3 to 12.3%. With repeated samples, the coefficient of variation will not exceed 12.3% and will not be below 9.3% in 95 cases out of 100.
Questions for self-control:

Problems for independent solution.
1. The average percentage of fat in milk during lactation of Kholmogory crossbred cows was as follows: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. Establish confidence intervals for the general mean at 95% confidence level (20 points).
2. On 400 hybrid rye plants, the first flowers appeared on average 70.5 days after sowing. The standard deviation was 6.9 days. Determine the error of the mean and confidence intervals for the general mean and variance at the significance level W= 0.05 and W= 0.01 (25 points).
3. When studying the length of leaves of 502 specimens of garden strawberries, the following data were obtained:
 = 7.86 cm; σ = 1.32 cm,
= 7.86 cm; σ = 1.32 cm,  =± 0.06 cm. Determine confidence intervals for the arithmetic population mean with significance levels of 0.01; 0.02; 0.05. (25 points).
=± 0.06 cm. Determine confidence intervals for the arithmetic population mean with significance levels of 0.01; 0.02; 0.05. (25 points).
4. In a study of 150 adult men, the average height was 167 cm, and σ = 6 cm. What are the limits of the general mean and general dispersion with a confidence probability of 0.99 and 0.95? (25 points).
5. The distribution of calcium in the blood serum of monkeys is characterized by the following selective indicators:
 = 11.94 mg%, σ
= 1,27, n
= 100. Construct a 95% confidence interval for the general mean of this distribution. Calculate the coefficient of variation (25 points).
= 11.94 mg%, σ
= 1,27, n
= 100. Construct a 95% confidence interval for the general mean of this distribution. Calculate the coefficient of variation (25 points).
6. The total nitrogen content in the blood plasma of albino rats at the age of 37 and 180 days was studied. The results are expressed in grams per 100 cm 3 of plasma. At the age of 37 days, 9 rats had: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. At the age of 180 days, 8 rats had: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. Set confidence intervals for the difference at a confidence level of 0.95 (50 points).
7. Determine the boundaries of the 95% confidence interval for the general variance of the distribution of calcium (mg%) in the blood serum of monkeys, if for this distribution the sample size is n = 100, statistical error of the sample variance s σ 2 = 1.60 (40 points).
8. Determine the boundaries of the 95% confidence interval for the general variance of the distribution of 40 wheat spikelets along the length (σ 2 = 40.87 mm 2). (25 points).
9. Smoking is considered the main factor predisposing to obstructive pulmonary diseases. Passive smoking is not considered such a factor. Scientists doubted the harmlessness of passive smoking and examined the airway patency of non-smokers, passive and active smokers. To characterize the state of the respiratory tract, we took one of the indicators of external respiration function - the maximum volumetric flow rate of mid-expiration. A decrease in this indicator is a sign of airway obstruction. The survey data are shown in the table.
|
Number of people examined |
Maximum mid-expiratory flow rate, l/s |
||
|
Standard deviation |
|||
|
Non-smokers |
|||
|
work in a non-smoking area | |||
|
working in a smoky room | |||
|
Smoking |
|||
|
smokers do not big number cigarettes | |||
|
average number of cigarette smokers | |||
|
smoke a large number of cigarettes | |||
Using the table data, find 95% confidence intervals for the overall mean and overall variance for each group. What are the differences between the groups? Present the results graphically (25 points).
10. Determine the boundaries of the 95% and 99% confidence intervals for the general variance in the number of piglets in 64 farrows, if the statistical error of the sample variance s σ 2 = 8.25 (30 points).
11. It is known that the average weight of rabbits is 2.1 kg. Determine the boundaries of the 95% and 99% confidence intervals for the general mean and variance at n= 30, σ = 0.56 kg (25 points).
12. The grain content of the ear was measured for 100 ears ( X), ear length ( Y) and the mass of grain in the ear ( Z). Find confidence intervals for the general mean and variance at P 1
= 0,95, P 2
= 0,99, P 3
= 0.999 if
 = 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 points).
= 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 points).
13. In 100 randomly selected ears of winter wheat, the number of spikelets was counted. The sample population was characterized by the following indicators:
 = 15 spikelets and σ = 2.28 pcs. Determine with what accuracy the average result was obtained (
= 15 spikelets and σ = 2.28 pcs. Determine with what accuracy the average result was obtained (  ) and construct a confidence interval for the general mean and variance at 95% and 99% significance levels (30 points).
) and construct a confidence interval for the general mean and variance at 95% and 99% significance levels (30 points).
14. Number of ribs on fossil mollusk shells Orthambonites calligramma:
It is known that n = 19, σ = 4.25. Determine the boundaries of the confidence interval for the general mean and general variance at the significance level W = 0.01 (25 points).
15. To determine milk yield on a commercial dairy farm, the productivity of 15 cows was determined daily. According to data for the year, each cow gave on average the following amount of milk per day (l): 22; 19; 25; 20; 27; 17; thirty; 21; 18; 24; 26; 23; 25; 20; 24. Construct confidence intervals for the general variance and the arithmetic mean. Can we expect the average annual milk yield per cow to be 10,000 liters? (50 points).
16. In order to determine the average wheat yield for the agricultural enterprise, mowing was carried out on trial plots of 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 and 2 hectares. Productivity (c/ha) from the plots was 39.4; 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; 29 respectively. Construct confidence intervals for the general variance and arithmetic mean. Can we expect that the average agricultural yield will be 42 c/ha? (50 points).
Confidence interval
Confidence interval- a term used in mathematical statistics for interval (as opposed to point) estimation of statistical parameters, which is preferable when the sample size is small. A confidence interval is one that covers an unknown parameter with a given reliability.
The method of confidence intervals was developed by the American statistician Jerzy Neumann, based on the ideas of the English statistician Ronald Fisher.
Definition
Confidence interval of the parameter θ random variable distribution X with confidence level 100 p%, generated by the sample ( x 1 ,…,x n), is called an interval with boundaries ( x 1 ,…,x n) and ( x 1 ,…,x n), which are realizations of random variables L(X 1 ,…,X n) and U(X 1 ,…,X n), such that
.The boundary points of the confidence interval are called confidence limits.
An intuition-based interpretation of the confidence interval would be: if p is large (say 0.95 or 0.99), then the confidence interval almost certainly contains the true value θ .
Another interpretation of the concept of a confidence interval: it can be considered as an interval of parameter values θ compatible with experimental data and not contradicting them.
Examples
- Confidence interval for the mathematical expectation of a normal sample;
- Confidence interval for normal sample variance.
Bayesian confidence interval
In Bayesian statistics, there is a similar but different in some key details definition of a confidence interval. Here, the estimated parameter itself is considered a random variable with some given prior distribution (in the simplest case, uniform), and the sample is fixed (in classical statistics everything is exactly the opposite). A Bayesian confidence interval is an interval covering the parameter value with the posterior probability:
.In general, classical and Bayesian confidence intervals are different. In the English-language literature, the Bayesian confidence interval is usually called the term credible interval, and the classic one - confidence interval.
Notes
SourcesWikimedia Foundation. 2010.
- Kids (film)
- Colonist
See what “Confidence interval” is in other dictionaries:
Confidence interval- an interval calculated from sample data, which with a given probability (confidence) covers the unknown true value of the estimated distribution parameter. Source: GOST 20522 96: Soils. Methods for statistical processing of results... Dictionary-reference book of terms of normative and technical documentation
confidence interval- for a scalar parameter of the population, this is a segment that most likely contains this parameter. This phrase is meaningless without further elaboration. Since the boundaries of the confidence interval are estimated from the sample, it is natural to... ... Dictionary of Sociological Statistics
CONFIDENCE INTERVAL- a method of estimating parameters that differs from point estimation. Let the sample x1, . . ., xn from a distribution with probability density f(x, α), and a*=a*(x1, . . ., xn) estimate α, g(a*, α) probability density estimate. Are looking for… … Geological encyclopedia
CONFIDENCE INTERVAL- (confidence interval) An interval in which the reliability of the parameter value for the population obtained on the basis of a sample survey has a certain degree of probability, for example 95%, which is due to the sample itself. Width… … Economic dictionary
confidence interval- is the interval in which the true value of the determined quantity is located with a given confidence probability. General chemistry: textbook / A. V. Zholnin ... Chemical terms
Confidence interval CI- Confidence interval, CI * data interval, CI * confidence interval interval of the characteristic value, calculated for k.l. distribution parameter (for example, the average value of a characteristic) across the sample and with a certain probability (for example, 95% for 95% ... Genetics. encyclopedic Dictionary
CONFIDENCE INTERVAL- a concept that arises when estimating a statistical parameter. distribution by interval of values. D. and. for parameter q, corresponding to this coefficient. trust P is equal to such an interval (q1, q2) that for any probability distribution of inequality... ... Physical encyclopedia
confidence interval- - Telecommunications topics, basic concepts EN confidence interval ... Technical Translator's Guide
confidence interval- pasikliovimo intervalas statusas T sritis Standartizacija ir metrologija apibrėžtis Dydžio verčių intervalas, kuriame su pasirinktąja tikimybe yra matavimo rezultato vertė. atitikmenys: engl. confidence interval vok. Vertrauensbereich, m rus.… … Penkiakalbis aiškinamasis metrologijos terminų žodynas
confidence interval- pasikliovimo intervalas statusas T sritis chemija apibrėžtis Dydžio verčių intervalas, kuriame su pasirinktąja tikimybe yra matavimo rezultatų vertė. atitikmenys: engl. confidence interval rus. trust area; confidence interval... Chemijos terminų aiškinamasis žodynas