Steps
Calculating sample variance
-
Record the sample values. In most cases, statisticians only have access to samples of specific populations. For example, as a rule, statisticians do not analyze the cost of maintaining the totality of all cars in Russia - they analyze a random sample of several thousand cars. Such a sample will help determine the average cost of a car, but, most likely, the resulting value will be far from the real one.
- For example, let's analyze the number of buns sold in a cafe over 6 days, taken in random order. The sample looks like this: 17, 15, 23, 7, 9, 13. This is a sample, not a population, because we do not have data on buns sold for each day the cafe is open.
- If you are given a population rather than a sample of values, continue to the next section.
-
Write down a formula to calculate sample variance. Dispersion is a measure of the spread of values of a certain quantity. The closer the variance value is to zero, the closer the values are grouped together. When working with a sample of values, use the following formula to calculate variance:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))– this is dispersion. Dispersion is measured in square units.
- x i (\displaystyle x_(i))– each value in the sample.
- x i (\displaystyle x_(i)) you need to subtract x̅, square it, and then add the results.
- x̅ – sample mean (sample mean).
- n – number of values in the sample.
-
Calculate the sample mean. It is denoted as x̅. The sample mean is calculated as a simple arithmetic mean: add up all the values in the sample, and then divide the result by the number of values in the sample.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
Now divide the result by the number of values in the sample (in our example there are 6): 84 ÷ 6 = 14.
Sample mean x̅ = 14. - The sample mean is the central value around which the values in the sample are distributed. If the values in the sample cluster around the sample mean, then the variance is small; otherwise the variance is large.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Subtract the sample mean from each value in the sample. Now calculate the difference x i (\displaystyle x_(i))- x̅, where x i (\displaystyle x_(i))– each value in the sample. Each result obtained indicates the degree of deviation of a particular value from the sample mean, that is, how far this value is from the sample mean.
- In our example:
x 1 (\displaystyle x_(1))- x = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - The correctness of the results obtained is easy to check, since their sum should be equal to zero. This is related to the determination of the average value, since negative values (distances from the average value to smaller values) are completely compensated positive values(distances from average to large values).
- In our example:
-
As noted above, the sum of the differences x i (\displaystyle x_(i))- x̅ must be equal to zero. It means that average variance is always equal to zero, which does not give any idea about the spread of values of a certain quantity. To solve this problem, square each difference x i (\displaystyle x_(i))- x̅. This will result in you only getting positive numbers, which will never add up to 0.
- In our example:
(x 1 (\displaystyle x_(1))- x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))- x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - You found the square of the difference - x̅) 2 (\displaystyle ^(2)) for each value in the sample.
- In our example:
-
Calculate the sum of the squares of the differences. That is, find that part of the formula that is written like this: ∑[( x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))]. Here the sign Σ means the sum of squared differences for each value x i (\displaystyle x_(i)) in the sample. You have already found the squared differences (x i (\displaystyle (x_(i))- x̅) 2 (\displaystyle ^(2)) for each value x i (\displaystyle x_(i)) in the sample; now just add these squares.
- In our example: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Divide the result by n - 1, where n is the number of values in the sample. Some time ago, to calculate sample variance, statisticians simply divided the result by n; in this case you will get the mean of the squared variance, which is ideal for describing the variance of a given sample. But remember that any sample is only a small part population values. If you take another sample and perform the same calculations, you will get a different result. As it turns out, dividing by n - 1 (rather than just n) gives a more accurate estimate of the population variance, which is what you're interested in. Division by n – 1 has become common, so it is included in the formula for calculating sample variance.
- In our example, the sample includes 6 values, that is, n = 6.
Sample variance = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- In our example, the sample includes 6 values, that is, n = 6.
-
The difference between variance and standard deviation. Note that the formula contains an exponent, so the dispersion is measured in square units of the value being analyzed. Sometimes such a magnitude is quite difficult to operate; in such cases, use the standard deviation, which is equal to square root from dispersion. That is why the sample variance is denoted as s 2 (\displaystyle s^(2)), A standard deviation samples - how s (\displaystyle s).
- In our example, the standard deviation of the sample is: s = √33.2 = 5.76.
Calculating Population Variance
-
Analyze some set of values. The set includes all values of the quantity under consideration. For example, if you are studying the age of residents Leningrad region, then the population includes the ages of all residents of this area. When working with a population, it is recommended to create a table and enter the population values into it. Consider the following example:
- In a certain room there are 6 aquariums. Each aquarium contains the following number of fish:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- In a certain room there are 6 aquariums. Each aquarium contains the following number of fish:
-
Write down a formula to calculate the population variance. Since the totality includes all values of a certain quantity, the formula below allows us to obtain exact value population variances. To distinguish population variance from sample variance (which is only an estimate), statisticians use various variables:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n
- σ 2 (\displaystyle ^(2))– population dispersion (read as “sigma squared”). Dispersion is measured in square units.
- x i (\displaystyle x_(i))– each value in its entirety.
- Σ – sum sign. That is, from each value x i (\displaystyle x_(i)) you need to subtract μ, square it, and then add the results.
- μ – population mean.
- n – number of values in the population.
-
Calculate the population mean. When working with a population, its mean is denoted as μ (mu). The population mean is calculated as a simple arithmetic mean: add up all the values in the population, and then divide the result by the number of values in the population.
- Keep in mind that averages are not always calculated as the arithmetic mean.
- In our example, the population mean: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Subtract the population mean from each value in the population. The closer the difference is to zero, the closer specific meaning to the population mean. Find the difference between each value in the population and its mean, and you will get a first idea of the distribution of values.
- In our example:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- In our example:
-
Square each result obtained. The difference values will be both positive and negative; If these values are plotted on a number line, they will lie to the right and left of the population mean. This is not good for calculating variance because positive and negative numbers cancel each other out. So square each difference to get exclusively positive numbers.
- In our example:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) for each population value (from i = 1 to i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), Where x n (\displaystyle x_(n))– the last value in the population. - To calculate the average value of the results obtained, you need to find their sum and divide it by n:(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/n
- Now let's write down the above explanation using variables: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n and get a formula for calculating the population variance.
- In our example:
The main generalizing indicators of variation in statistics are dispersions and standard deviations.
Dispersion this arithmetic mean squared deviations of each characteristic value from the overall average. The variance is usually called the mean square of deviations and is denoted by 2. Depending on the source data, the variance can be calculated using the simple or weighted arithmetic mean:
unweighted (simple) variance;
 variance weighted.
variance weighted.
Standard deviation this is a generalizing characteristic of absolute sizes variations signs in the aggregate. It is expressed in the same units of measurement as the attribute (in meters, tons, percentage, hectares, etc.).
The standard deviation is the square root of the variance and is denoted by :
 standard deviation unweighted;
standard deviation unweighted;
 weighted standard deviation.
weighted standard deviation.
The standard deviation is a measure of the reliability of the mean. The smaller the standard deviation, the better the arithmetic mean reflects the entire represented population.
The calculation of the standard deviation is preceded by the calculation of the variance.
The procedure for calculating the weighted variance is as follows:
1) determine the weighted arithmetic mean:
2) calculate the deviations of the options from the average:
3) square the deviation of each option from the average:
4) multiply the squares of deviations by weights (frequencies):
5) summarize the resulting products:
![]()
6) the resulting amount is divided by the sum of the weights:

Example 2.1

Let's calculate the weighted arithmetic mean:

The values of deviations from the mean and their squares are presented in the table. Let's define the variance:

The standard deviation will be equal to:

If the source data is presented in the form of interval distribution series , then you first need to determine the discrete value of the attribute, and then apply the described method.
Example 2.2
Let us show the calculation of variance for an interval series using data on the distribution of the sown area of a collective farm according to wheat yield.

The arithmetic mean is:

Let's calculate the variance:

6.3. Calculation of variance using a formula based on individual data
Calculation technique variances complicated, but large values options and frequencies can be overwhelming. Calculations can be simplified using the properties of dispersion.
The dispersion has the following properties.
1. Reducing or increasing the weights (frequencies) of a varying characteristic by a certain number of times does not change the dispersion.
2. Decrease or increase each value of a characteristic by the same constant amount A does not change the dispersion.
3. Decrease or increase each value of a characteristic by a certain number of times k respectively reduces or increases the variance in k 2 times standard deviation in k once.
4. The dispersion of a characteristic relative to an arbitrary value is always greater than the dispersion relative to the arithmetic mean per square of the difference between the average and arbitrary values:
![]()
If A 0, then we arrive at the following equality:
that is, the variance of the characteristic is equal to the difference between the mean square of the characteristic values and the square of the mean.
Each property can be used independently or in combination with others when calculating variance.
The procedure for calculating variance is simple:
1) determine arithmetic mean :
2) square the arithmetic mean:

3) square the deviation of each variant of the series:
X i 2 .
4) find the sum of squares of the options:
5) divide the sum of the squares of the options by their number, i.e. determine the average square:
6) determine the difference between the mean square of the characteristic and the square of the mean:
Example 3.1 The following data is available on worker productivity:

Let's make the following calculations:
![]()
Along with studying the variation of a characteristic throughout the entire population as a whole, it is often necessary to trace quantitative changes in the characteristic across the groups into which the population is divided, as well as between groups. This study of variation is achieved through calculation and analysis various types variances.
There are total, intergroup and intragroup variances.
Total variance σ 2 measures the variation of a trait throughout the entire population under the influence of all factors that caused this variation.
Intergroup variance (δ) characterizes systematic variation, i.e. differences in the value of the studied trait that arise under the influence of the factor trait that forms the basis of the group. It is calculated using the formula: 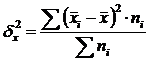 .
.
Within-group variance (σ) reflects random variation, i.e. part of the variation that occurs under the influence of unaccounted factors and does not depend on the factor-attribute that forms the basis of the group. It is calculated by the formula: 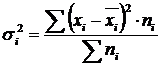 .
.
Average of within-group variances:  .
.
There is a law connecting 3 types of dispersion. The total variance is equal to the sum of the average of the within-group and between-group variance: ![]() .
.
This ratio is called rule for adding variances.
The analysis widely uses an indicator representing the share of intergroup variance in total variance. It's called empirical coefficient of determination (η 2): .
The square root of the empirical coefficient of determination is called empirical correlation ratio (η):
 .
.
It characterizes the influence of the characteristic that forms the basis of the group on the variation of the resulting characteristic. The empirical correlation ratio ranges from 0 to 1.
Let's show it practical use using the following example (Table 1).
Example No. 1. Table 1 - Labor productivity of two groups of workers in one of the workshops of NPO "Cyclone"
Let's calculate the overall and group means and variances:
The initial data for calculating the average of intragroup and intergroup variance are presented in table. 2.
table 2
Calculation and δ 2 for two groups of workers.
|
Worker groups | Number of workers, people | Average, children/shift | Dispersion |
| Completed technical training | 5 | 95 | 42,0 |
| Those who have not completed technical training | 5 | 81 | 231,2 |
| All workers | 10 | 88 | 185,6 |
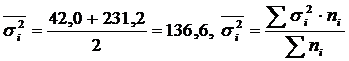 .
.
Intergroup variance
Total variance:
Thus, the empirical correlation ratio: .
Along with variation in quantitative characteristics, variation in qualitative characteristics can also be observed. This study of variation is achieved by calculating the following types dispersions:
The within-group dispersion of the share is determined by the formula
Where n i– number of units in separate groups.The share of the studied characteristic in the entire population, which is determined by the formula:
The three types of variance are related to each other as follows:
This relation of variances is called the theorem of addition of variances of the trait share.
Variance is a measure of dispersion that describes the comparative deviation between data values and the mean. It is the most used measure of dispersion in statistics, calculated by summing and squaring the deviation of each data value from the mean. The formula for calculating variance is given below:
![]()
s 2 – sample variance;
x av—sample mean;
n — sample size (number of data values),
(x i – x avg) is the deviation from the average value for each value of the data set.
To better understand the formula, let's look at an example. I don’t really like cooking, so I rarely do it. However, in order not to starve, from time to time I have to go to the stove to implement the plan of saturating my body with proteins, fats and carbohydrates. The data set below shows how many times Renat cooks every month:
The first step in calculating variance is to determine the sample mean, which in our example is 7.8 times per month. The rest of the calculations can be made easier using the following table.

The final phase of calculating variance looks like this:
![]()
For those who like to do all the calculations in one go, the equation would look like this:
Using the raw count method (cooking example)
There are more effective method calculation of variance, known as the "raw counting" method. Although the equation may seem quite cumbersome at first glance, it is actually not that scary. You can make sure of this, and then decide which method you like best.

is the sum of each data value after squaring,
is the square of the sum of all data values.
Don't lose your mind right now. Let's put this all into a table and you will see that there are fewer calculations here than in the previous example.


As you can see, the result was the same as when using the previous method. Advantages this method become apparent as the sample size (n) increases.
Variance calculation in Excel
As you probably already guessed, Excel has a formula that allows you to calculate variance. Moreover, starting with Excel 2010, you can find 4 types of variance formula:
1) VARIANCE.V – Returns the variance of the sample. Boolean values and text are ignored.
2) DISP.G - Returns the variance of the population. Boolean values and text are ignored.
3) VARIANCE - Returns the variance of the sample, taking into account Boolean and text values.
4) VARIANCE - Returns the variance of the population, taking into account logical and text values.
First, let's understand the difference between a sample and a population. The purpose of descriptive statistics is to summarize or display data so that you quickly get the big picture, an overview so to speak. Statistical inference allows you to make inferences about a population based on a sample of data from that population. The population represents all possible outcomes or measurements that are of interest to us. A sample is a subset of a population.
For example, we are interested in the totality of a group of students from one of the Russian universities and we need to determine the average score of the group. We can calculate the average performance of students, and then the resulting figure will be a parameter, since the whole population will be involved in our calculations. However, if we want to calculate the GPA of all students in our country, then this group will be our sample.
The difference in the formula for calculating variance between a sample and a population is the denominator. Where for the sample it will be equal to (n-1), and for the general population only n.
Now let's look at the functions for calculating variance with endings A, the description of which states that text and logical values are taken into account in the calculation. In this case, when calculating the variance of a certain data array, where there are not numeric values Excel will interpret text and false Boolean values as equal to 0, and true Boolean values as equal to 1.
So, if you have a data array, calculating its variance will not be difficult using one of the Excel functions listed above.

Variance (scattering) of a random variable is the mathematical expectation of the squared deviation of a random variable from its mathematical expectation:
To calculate the variance, you can use a slightly modified formula
because M(X), 2 and  – constant values. Thus,
– constant values. Thus,
4.2.2. Dispersion properties
Property 1. The variance of a constant value is zero. Indeed, by definition
Property 2. The constant factor can be taken out of the dispersion sign by squaring it.
Proof
Centered a random variable is the deviation of a random variable from its mathematical expectation:

A centered quantity has two properties convenient for transformation:
Property 3. If random variables X and Y are independent, then
Proof. Let's denote  . Then.
. Then.
In the second term, due to the independence of random variables and the properties of centered random variables
Example 4.5. If a And b– constants, thenD (aX+b)=
D(aX)+D(b)= .
.
4.2.3. Standard deviation
Dispersion, as a characteristic of the spread of a random variable, has one drawback. If, for example, X– the measurement error has a dimension MM, then the dispersion has the dimension  . Therefore, they often prefer to use another scatter characteristic - standard deviation
, which is equal to the square root of the variance
. Therefore, they often prefer to use another scatter characteristic - standard deviation
, which is equal to the square root of the variance

The standard deviation has the same dimension as itself random value.
Example 4.6. Variance of the number of occurrences of an event in an independent trial design
Produced n independent trials and the probability of an event occurring in each trial is R. Let us express, as before, the number of occurrences of the event X through the number of occurrences of the event in individual experiments:
Since the experiments are independent, the random variables associated with the experiments  independent. And due to independence
independent. And due to independence  we have
we have
But each of the random variables has a distribution law (example 3.2)
|
| ||

And  (example 4.4). Therefore, by definition of variance:
(example 4.4). Therefore, by definition of variance:
Where q=1- p.
As a result we have  ,
,
Standard deviation of the number of occurrences of an event in n independent experiments equal  .
.
4.3. Moments of random variables
In addition to those already considered, random variables have many other numerical characteristics.
The starting moment
k X
( ) is called the mathematical expectation k-th power of this random variable.
) is called the mathematical expectation k-th power of this random variable.
Central moment k th order random variable X called mathematical expectation k-th power of the corresponding centered quantity.

It is easy to see that the first-order central moment is always equal to zero, the second-order central moment is equal to the dispersion, since .
The third-order central moment gives an idea of the asymmetry of the distribution of a random variable. Moments of order higher than the second are used relatively rarely, so we will limit ourselves only to the concepts themselves.
4.4. Examples of finding distribution laws
Let's consider examples of finding the distribution laws of random variables and their numerical characteristics.
Example 4.7.
Draw up a law for the distribution of the number of hits on a target with three shots at a target, if the probability of a hit with each shot is 0.4. Find the integral function F(X) for the resulting distribution of a discrete random variable X and draw a graph of it. Find the expected value M(X)
, variance D(X)
and standard deviation  (X) random variable X.
(X) random variable X.
Solution
1) Discrete random variable X– the number of hits on the target with three shots – can take four values: 0, 1, 2, 3 . The probability that she will accept each of them is found using Bernoulli’s formula with: n=3,p=0,4,q=1- p=0.6 and m=0, 1, 2, 3:
Let's get the probabilities of possible values X:;
Let’s compose the desired law of distribution of a random variable X:
Control: 0.216+0.432+0.288+0.064=1.
Let's construct a distribution polygon of the resulting random variable X. To do this, in the rectangular coordinate system we mark the points (0; 0.216), (1; 0.432), (2; 0.288), (3; 0.064). Let us connect these points with straight line segments, the resulting broken line is the desired distribution polygon (Fig. 4.1).

2) If x  0, then F(X)=0. Indeed, for values less than zero, the value X does not accept. Therefore, for all X
0, then F(X)=0. Indeed, for values less than zero, the value X does not accept. Therefore, for all X 0, using the definition F(X), we get F(X)=P(X<
x)
=0 (as the probability of an impossible event).
0, using the definition F(X), we get F(X)=P(X<
x)
=0 (as the probability of an impossible event).
If 0  , That F(X)
=0.216. Indeed, in this case F(X)=P(X<
x)
=
=P(-
, That F(X)
=0.216. Indeed, in this case F(X)=P(X<
x)
=
=P(-
 <
X
<
X  0)+
P(0<
X<
x)
=0,216+0=0,216.
0)+
P(0<
X<
x)
=0,216+0=0,216.
If we take, for example, X=0.2, then F(0,2)=P(X<0,2) . But the probability of an event X<0,2 равна 0,216, так как случайная величинаX only in one case does it take a value less than 0.2, namely 0 with probability 0.216.
If 1  , That
, That
Really, X can take the value 0 with probability 0.216 and the value 1 with probability 0.432; therefore, one of these meanings, no matter which, X can accept (according to the theorem of addition of probabilities of incompatible events) with a probability of 0.648.
If 2  , then, arguing similarly, we get F(X)=0.216+0.432 + + 0.288=0.936. Indeed, let, for example, X=3. Then F(3)=P(X<3)
expresses the probability of an event X<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF(X).
, then, arguing similarly, we get F(X)=0.216+0.432 + + 0.288=0.936. Indeed, let, for example, X=3. Then F(3)=P(X<3)
expresses the probability of an event X<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF(X).
If x>3, then F(X)=0.216+0.432+0.288+0.064=1. Indeed, the event X is reliable and its probability is equal to one, and X>3 – impossible. Considering that
is reliable and its probability is equal to one, and X>3 – impossible. Considering that
F(X)=P(X<
x)
=P(X  3)
+
P(3<
X<
x)
, we get the indicated result.
3)
+
P(3<
X<
x)
, we get the indicated result.
So, the required integral distribution function of the random variable X is obtained:
F(x)
=

the graph of which is shown in Fig. 4.2.

3) The mathematical expectation of a discrete random variable is equal to the sum of the products of all possible values X on their probabilities:
M(X)=0=1,2.
That is, on average, there is one hit on the target with three shots.
The variance can be calculated from the definition of variance D(X)=
M(X-
M(X))
 or use the formula D(X)=
M(X
or use the formula D(X)=
M(X  , which leads to the goal faster.
, which leads to the goal faster.
Let's write the law of distribution of a random variable X  :
:
Let's find the mathematical expectation for X :
:
M(X  )
= 04
)
= 04 = 2,16.
= 2,16.
Let's calculate the required variance:
D(X)
=
M(X  )
– (M(X))
)
– (M(X))
 = 2,16 – (1,2)
= 2,16 – (1,2) = 0,72.
= 0,72.
We find the standard deviation using the formula
 (X)
=
(X)
=
 = 0,848.
= 0,848.
Interval ( M-
 ;
M+
;
M+
 ) = (1.2-0.85; 1.2+0.85) = (0.35; 2.05) – interval of the most probable values of the random variable X, it contains the values 1 and 2.
) = (1.2-0.85; 1.2+0.85) = (0.35; 2.05) – interval of the most probable values of the random variable X, it contains the values 1 and 2.
Example 4.8.
Given a differential distribution function (density function) of a continuous random variable X:
 f(x)
=
f(x)
=
1) Determine the constant parameter a.
2) Find the integral function F(x) .
3) Build function graphs f(x) And F(x) .
4) Find the probability in two ways P(0.5<
X  1,5)
And P(1,5<
X<3,5)
.
1,5)
And P(1,5<
X<3,5)
.
5). Find the expected value M(X), variance D(X) and standard deviation  random variable X.
random variable X.
Solution
1) Differential function by property f(x)
must satisfy the condition  .
.
Let us calculate this improper integral for this function f(x) :

Substituting this result into the left side of the equality, we get that A=1. In the condition for f(x)
replace the parameter A by 1: 

2) To find F(x) let's use the formula
 .
.
If x  , That
, That 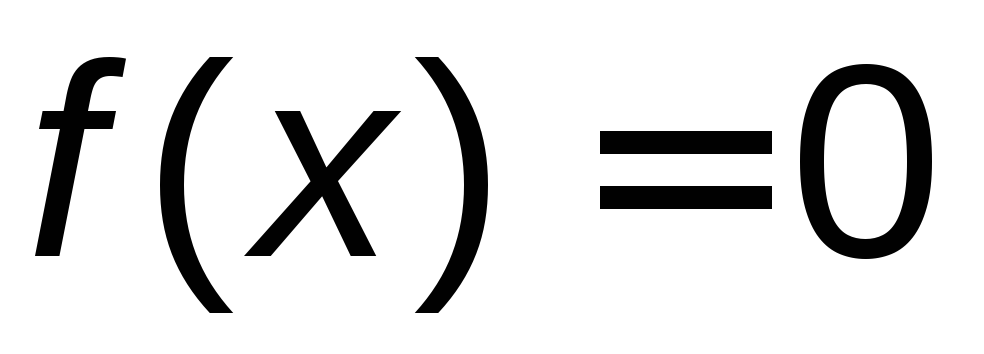 , hence,
, hence, 
If 1  That
That
If x>2, then
So, the required integral function F(x) has the form:

3) Let's build graphs of functions f(x) And F(x) (Fig. 4.3 and 4.4).


4) Probability of a random variable falling into a given interval (A,b)
calculated by the formula  , if the function is known f(x),
and according to the formula P(a
<
X
<
b)
=
F(b)
–
F(a),
if the function is known
F(x).
, if the function is known f(x),
and according to the formula P(a
<
X
<
b)
=
F(b)
–
F(a),
if the function is known
F(x).
We'll find  using two formulas and compare the results. By condition a=0.5;b=1,5;
function f(X)
specified in point 1). Therefore, the required probability according to the formula is equal to:
using two formulas and compare the results. By condition a=0.5;b=1,5;
function f(X)
specified in point 1). Therefore, the required probability according to the formula is equal to:
The same probability can be calculated using formula b) through the increment obtained in step 2). integral function F(x) on this interval:
Because F(0,5)=0.
Similarly we find 
because F(3,5)=1.
5) To find the mathematical expectation M(X) let's use the formula  Function f(x)
given in the solution to point 1), it is equal to zero outside the interval (1,2]:
Function f(x)
given in the solution to point 1), it is equal to zero outside the interval (1,2]:

 Variance of a continuous random variable D(X) is determined by equality
Variance of a continuous random variable D(X) is determined by equality
 , or the equivalent equality
, or the equivalent equality

 .
.
For  finding D(X)
Let's use the last formula and take into account that all possible values f(x)
belong to the interval (1,2]:
finding D(X)
Let's use the last formula and take into account that all possible values f(x)
belong to the interval (1,2]:
Standard deviation  =
= =0,276.
=0,276.
Interval of the most probable values of a random variable X equals
(M-  ,M+
,M+  )
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).
)
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).